Instruction Set Architecture
Triton VM is a stack machine with RAM. It is a Harvard architecture with read-only memory for the program. The arithmetization of the VM is defined over the B-field where is the Oxfoi prime, i.e., .1 This means the registers and memory elements take values from , and the transition function gives rise to low-degree transition verification polynomials from the ring of multivariate polynomials over .
At certain points in the course of arithmetization we need an extension field over to ensure sufficient soundness. To this end we use , i.e., the quotient ring of remainders of polynomials after division by the Shah polynomial, . We refer to this field as the X-field for short, and its elements as X-field elements.
Instructions have variable width:
they either consist of one word, i.e., one B-field element, or of two words, i.e., two B-field elements.
An example for a single-word instruction is add, adding the two elements on top of the stack, leaving the result as the new top of the stack.
An example for a double-word instruction is push + arg, pushing arg to the stack.
Triton VM has two interfaces for data input, one for public and one for secret data, and one interface for data output, whose data is always public. The public interfaces differ from the private one, especially regarding their arithmetization.
-
The name “Oxfoi” comes from the prime’s hexadecimal representation
0xffffffff00000001. ↩
Data Structures
Memory
The term memory refers to a data structure that gives read access (and possibly write access, too) to elements indicated by an address. Regardless of the data structure, the address lives in the B-field. There are four separate notions of memory:
- Program Memory, from which the VM reads instructions.
- Op Stack Memory, which stores the operational stack.
- RAM, to which the VM can read and write field elements.
- Jump Stack Memory, which stores the entire jump stack.
Program Memory
Program memory holds the instructions of the program currently executed by Triton VM. It is immutable.
Operational Stack
The stack is a last-in;first-out data structure that allows the program to store intermediate variables, pass arguments, and keep pointers to objects held in RAM. In this document, the operational stack is either referred to as just “stack” or, if more clarity is desired, “op stack.”
From the Virtual Machine’s point of view, the stack is a single, continuous object. The first 16 elements of the stack can be accessed very conveniently. Elements deeper in the stack require removing some of the higher elements, possibly after storing them in RAM.
For reasons of arithmetization, the stack is actually split into two distinct parts:
- the operational stack registers
st0throughst15, and - the Op Stack Underflow Memory.
The motivation and the interplay between the two parts is described and exemplified in arithmetization of the Op Stack table.
Random Access Memory
Triton VM has dedicated Random Access Memory.
It can hold up to many base field elements, where is the Oxfoi prime1.
Programs can read from and write to RAM using instructions read_mem
and write_mem.
The initial RAM is determined by the entity running Triton VM. Populating RAM this way can be beneficial for a program’s execution and proving time, especially if substantial amounts of data from the input streams needs to be persisted in RAM. This initialization is one form of secret input, and one of two mechanisms that make Triton VM a non-deterministic virtual machine. The other mechanism is dedicated instructions.
Jump Stack
Another last-in;first-out data structure, similar to the op stack.
The jump stack keeps track of return and destination addresses.
It changes only when control follows a call or
return instruction, and might change through the
recurse_or_return instruction.
Furthermore, executing instructions return,
recurse, and recurse_or_return
require a non-empty jump stack.
-
Of course, the machine running Triton VM might have stricter limitations: storing or accessing bits EiB of data is a non-trivial engineering feat. ↩
Registers
This section covers all registers. Only a subset of these registers relate to the instruction set; the remaining registers exist only to enable an efficient arithmetization and are marked with an asterisk (*). Each register directly corresponds to one column in the Processor Table.
| Register | Name | Purpose |
|---|---|---|
*clk | cycle counter | counts the number of cycles the program has been running for |
*IsPadding | padding indicator | indicates whether current state is only recorded to improve on STARK’s computational runtime |
ip | instruction pointer | contains the memory address (in Program Memory) of the instruction |
ci | current instruction | contains the current instruction |
nia | next instruction (or argument) | contains either the instruction at the next address in Program Memory, or the argument for the current instruction |
*ib0 through ib6 | instruction bit | decomposition of the instruction’s opcode used to keep the AIR degree low |
jsp | jump stack pointer | contains the memory address (in jump stack memory) of the top of the jump stack |
jso | jump stack origin | contains the value of the instruction pointer of the last call |
jsd | jump stack destination | contains the argument of the last call |
st0 through st15 | operational stack registers | contain explicit operational stack values |
*op_stack_pointer | operational stack pointer | the current size of the operational stack |
*hv0 through hv5 | helper variable registers | helper variables for some arithmetic operations |
*cjd_mul | clock jump difference lookup multiplicity | multiplicity with which the current clk is looked up by the Op Stack Table, RAM Table, and Jump Stack Table |
Instruction
Register ip, the instruction pointer, contains the address of the current instruction in
Program Memory.
The opcode of the current instruction is contained in
the register current instruction, or ci.
Register next instruction (or argument), or nia, either contains the next instruction or,
if it has one, the argument of the current instruction.
For reasons of arithmetization, ci is decomposed, giving rise to the instruction bit registers,
labeled ib0 through ib6.
Stack
The stack is represented by 16 registers called stack registers (st0 – st15) plus the op stack underflow memory.
The top 16 elements of the op stack are directly accessible, the remainder of the op stack, i.e, the part held in op stack underflow memory, is not.
In order to access elements of the op stack held in op stack underflow memory, the stack has to shrink by discarding elements from the top – potentially after writing them to RAM – thus moving lower elements into the stack registers.
For reasons of arithmetization, the stack always contains a minimum of 16 elements. Trying to run an instruction which would result in a stack of smaller total length than 16 crashes the VM.
Stack elements st0 through st10 are initially 0.
Stack elements st11 through st15, i.e., the very bottom of the stack, are initialized with the hash digest of the program that is being executed.
See the mechanics of program attestation for further explanations on stack initialization.
The register op_stack_pointer is not directly accessible by the program running in TritonVM.
It exists only to allow efficient arithmetization.
Helper Variables
Some instructions require helper variables in order to generate an efficient arithmetization.
To this end, there are 6 helper variable registers, labeled hv0 through hv5.
These registers are part of the arithmetization of the architecture, but not needed to define the instruction set.
Because they are only needed for some instructions, the helper variables are not generally defined.
For instruction group decompose_arg and instructions
skiz,
split,
eq,
merkle_step,
merkle_step_mem,
xx_dot_step, and
xb_dot_step,
the behavior is defined in the respective sections.
About Instructions
This section describes some general properties and behaviors of Triton VM’s instructions. The next section lists and describes all the instructions that Triton VM can execute.
Instruction Sizes
Most instructions are contained within a single, parameterless machine word.
They are considered single-word instructions.
An example of a single-word instruction is halt.
Some instructions take one machine word as argument and are so considered double-word instructions.
They are recognized by the form “instr + arg”.
An example of a double-word instruction is push + a, which takes immediate argument a.
Automatic Instruction Pointer Increment
Unless a different behavior is indicated, instructions increment the
instruction pointer ip by their size.
For example, instruction halt increments the ip by 1.
Instruction push increments the ip by 2.
Many control flow instructions manipulate the instruction pointer in
a manner deviating from this general scheme.
Non-Deterministic Instructions
Instructions divine and merkle_step
make Triton a virtual machine that can execute non-deterministic programs.
As programs go, this concept is somewhat unusual and benefits from additional explanation.
From the perspective of the program, the instruction divine makes some n elements magically
appear on the stack. It is not at all specified what those elements are, but generally speaking,
they have to be exactly correct, else execution fails. Hence, from the perspective of the program,
it just non-deterministically guesses the correct values in a moment of divine clarity.
Looking at the entire system, consisting of the VM, the program, and all inputs – both public and secret – execution is deterministic: the divined values were supplied as secret input and are read from there.
Hashing and Sponge Instructions
The instructions sponge_init,
sponge_absorb,
sponge_absorb_mem, and
sponge_squeeze are the interface
for using the Tip5 permutation in a
Sponge construction.
The capacity is never accessible to the program that’s being executed by Triton VM.
At any given time, at most one Sponge state exists.
In particular, Triton VM does not start with an initialized Sponge state.
If a program uses the Sponge state, the first Sponge instruction must be sponge_init;
otherwise, Triton VM will crash.
Only instruction sponge_init resets the state of the Sponge, and only the three Sponge
instructions influence the Sponge’s state.
Notably, executing instruction hash does not modify the Sponge’s state.
When using the Sponge instructions, it is the programmer’s responsibility to take care of proper input padding: Triton VM cannot know the number of elements that will be absorbed. For more information, see section 2.5 of the Tip5 paper.
Regarding Opcodes
An instruction’s operation code, or opcode, is the machine word uniquely identifying the instruction. For reasons of efficient arithmetization, certain properties of the instruction are encoded in the opcode. Concretely, interpreting the field element in standard representation:
- for all double-word instructions, the least significant bit is 1.
- for all instructions shrinking the operational stack, the second-to-least significant bit is 1.
- for all u32 instructions, the third-to-least significant bit is 1.
The first property is used by instruction skiz (see also its arithmetization). The second property helps with proving consistency of the Op Stack. The third property allows efficient arithmetization of the running product for the Permutation Argument between Processor Table and U32 Table.
Instructions
Triton VM’s instructions are (loosely and informally) grouped into the following categories:
- Stack Manipulation
- Control Flow
- Memory Access
- Hashing
- Base Field Arithmetic
- Bitwise Arithmetic
- Extension Field Arithmetic
- Input/Output
- Many-In-One
The following table is a summary of all instructions. For more details, read on below.
| Instruction | Description |
|---|---|
push + a | Push a onto the stack. |
pop + n | Pop the n top elements from the stack. |
divine + n | Push n non-deterministic elements to the stack. |
pick + i | Move stack element i to the top of the stack. |
place + i | Move the top of the stack to the position i. |
dup + i | Duplicate stack element i onto the stack. |
swap + i | Swap stack element i with the top of the stack. |
halt | Indicate graceful shutdown of the VM. |
nop | Do nothing. |
skiz | Conditionally skip the next instruction. |
call + d | Continue execution at address d. |
return | Return to the last call-site. |
recurse | Continue execution at the location last called. |
recurse_or_return | Either recurse or return. |
assert | Assert that the top of the stack is 1. |
read_mem + n | Read n elements from RAM. |
write_mem + n | Write n elements to RAM. |
hash | Hash the top of the stack. |
assert_vector | Assert equivalence of the two top quintuples. |
sponge_init | Initialize the Sponge state. |
sponge_absorb | Absorb the top of the stack into the Sponge state. |
sponge_absorb_mem | Absorb from RAM into the Sponge state. |
sponge_squeeze | Squeeze the Sponge state onto the stack. |
add | Add two base field elements. |
addi + a | Add a to the top of the stack. |
mul | Multiply two base field elements. |
invert | Base-field reciprocal of the top of the stack. |
eq | Compare the top two stack elements for equality. |
split | Split the top of the stack into 32-bit words. |
lt | Compare two elements for “less than”. |
and | Bitwise “and”. |
xor | Bitwise “xor”. |
log_2_floor | The log₂ of the top of the stack, rounded down. |
pow | The top of the stack to the power of its runner-up. |
div_mod | Division with remainder. |
pop_count | The hamming weight of the top of the stack. |
xx_add | Add two extension field elements. |
xx_mul | Multiply two extension field elements. |
x_invert | Extension-field reciprocal of the top of the stack. |
xb_mul | Multiply elements from the extension and base field. |
read_io + n | Read n elements from standard input. |
write_io + n | Write n elements to standard output. |
merkle_step | Helps traversing a Merkle tree using secret input. |
merkle_step_mem | Helps traversing a Merkle tree using RAM. |
xx_dot_step | Helps computing an extension field dot product. |
xb_dot_step | Helps computing a mixed-field dot product. |
Stack Manipulation
push + a
Opcode: 1
Pushes a onto the stack.
| old stack | new stack |
|---|---|
_ | _ a |
pop + n
Opcode: 3
Pops the n top elements from the stack.
1 ⩽ n ⩽ 5.
n | old stack | new stack |
|---|---|---|
| 1 | _ a | _ |
| 2 | _ b a | _ |
| 3 | _ c b a | _ |
| 4 | _ d c b a | _ |
| 5 | _ e d c b a | _ |
divine + n
Opcode: 9
Pushes n non-deterministic elements a to the stack.
1 ⩽ n ⩽ 5.
This is part of the interface for Triton VM’s secret input; see also the section regarding non-determinism.
The name of the instruction is the verb (not the adjective) meaning “to discover by intuition or insight.”
n | old stack | new stack |
|---|---|---|
| 1 | _ | _ a |
| 2 | _ | _ b a |
| 3 | _ | _ c b a |
| 4 | _ | _ d c b a |
| 5 | _ | _ e d c b a |
pick + i
Opcode: 17
Moves the element indicated by i to the top of the stack.
0 ⩽ i < 16.
i | old stack | new stack |
|---|---|---|
| 0 | _ d c b a x | _ d c b a x |
| 1 | _ d c b x a | _ d c b a x |
| 2 | _ d c x b a | _ d c b a x |
| 3 | _ d x c b a | _ d c b a x |
| 4 | _ x d c b a | _ d c b a x |
| … | … | … |
place + i
Opcode: 25
Moves the top of the stack to the indicated position i.
0 ⩽ i < 16.
i | old stack | new stack |
|---|---|---|
| 0 | _ d c b a x | _ d c b a x |
| 1 | _ d c b a x | _ d c b x a |
| 2 | _ d c b a x | _ d c x b a |
| 3 | _ d c b a x | _ d x c b a |
| 4 | _ d c b a x | _ x d c b a |
| … | … | … |
dup + i
Opcode: 33
Duplicates the element ith stack element and pushes it onto the stack.
0 ⩽ i < 16.
i | old stack | new stack |
|---|---|---|
| 0 | _ e d c b a | _ e d c b a a |
| 1 | _ e d c b a | _ e d c b a b |
| 2 | _ e d c b a | _ e d c b a c |
| 3 | _ e d c b a | _ e d c b a d |
| 4 | _ e d c b a | _ e d c b a e |
| … | … | … |
swap + i
Opcode: 41
Swaps the ith stack element with the top of the stack.
0 ⩽ i < 16.
i | old stack | new stack |
|---|---|---|
| 0 | _ e d c b a | _ e a c b a |
| 1 | _ e d c b a | _ e d c a b |
| 2 | _ e d c b a | _ e d a b c |
| 3 | _ e d c b a | _ e a c b d |
| 4 | _ e d c b a | _ a d c b e |
| … | … | … |
Control Flow
halt
Opcode: 0
Solves the halting problem (if the instruction is reached). Indicates graceful shutdown of the VM.
The only legal instruction following instruction halt is halt.
It is only possible to prove correct execution of a program if the last executed instruction is
halt.
nop
Opcode: 8
Does nothing.
skiz
Opcode: 2
Pop the top of the stack and skip the next instruction if the popped element is zero.
“skiz” stands for “skip if zero”.
An alternative perspective for this instruction is “execute if non-zero”, or “execute if”, or even
just “if”.
The amount by which skiz increases the instruction pointer ip depends on both the top of the
stack and the size of the next instruction
in the program (not the next instruction that gets actually
executed).
| next instruction’s size | old stack | new stack | old ip | new ip |
|---|---|---|---|---|
| any | _ a with a ≠ 0 | _ | ip | ip+1 |
| single word | _ 0 | _ | ip | ip+2 |
| double word | _ 0 | _ | ip | ip+3 |
call + d
Opcode: 49
Push address pair (ip+2, d) to the jump stack, and jump to absolute address d.
old ip | new ip | old jump stack | new jump stack |
|---|---|---|---|
ip | d | _ | _ (ip+2, d) |
return
Opcode: 16
Pop one address pair off the jump stack and jump to that pair’s return address (which is the pair’s first element).
Executing this instruction with an empty jump stack crashes Triton VM.
old ip | new ip | old jump stack | new jump stack |
|---|---|---|---|
ip | o | _ (o, d) | _ |
recurse
Opcode: 24
Peek at the top address pair of the jump stack and jump to that pair’s destination address (which is the pair’s second element).
Executing this instruction with an empty jump stack crashes Triton VM.
old ip | new ip | old jump stack | new jump stack |
|---|---|---|---|
ip | d | _ (o, d) | _ (o, d) |
recurse_or_return
Opcode: 32
Like recurse if st5 ≠ st6, like return if st5 = st6.
Instruction recurse_or_return behaves – surprise! – either like instruction recurse
or like instruction return.
The (deterministic) decision which behavior to exhibit is made at runtime and depends on stack
elements st5 and st6, the stack elements at indices 5 and 6.
If st5 ≠ st6, then recurse_or_return acts like instruction recurse, else like
return.
The instruction is designed to facilitate loops using pointer equality as termination condition and
to play nicely with instructions merkle_step and
merkle_step_mem.
Executing this instruction with an empty jump stack crashes Triton VM.
old ip | new ip | old jump stack | new jump stack | |
|---|---|---|---|---|
st5 ≠ st6 | ip | d | _ (o, d) | _ (o, d) |
st5 = st6 | ip | o | _ (o, d) | _ |
assert
Opcode: 10
Pops a if a = 1, else crashes the virtual machine.
| old stack | new stack |
|---|---|
_ a | _ |
Memory Access
read_mem + n
Opcode: 57
Interprets the top of the stack, i.e., st0 as a pointer p into
RAM.
Reads consecutive values from RAM at address p and puts them onto the op
stack below st0.
Decrements the RAM pointer, i.e., the top of the stack, by n.
1 ⩽ n ⩽ 5.
Let the RAM at address p contain a, at address p+1 contain b, and so on.
Then, this instruction behaves as follows:
i | old stack | new stack |
|---|---|---|
1 | _ p | _ a p-1 |
2 | _ p+1 | _ b a p-1 |
3 | _ p+2 | _ c b a p-1 |
4 | _ p+3 | _ d c b a p-1 |
5 | _ p+4 | _ e d c b a p-1 |
write_mem + n
Opcode: 11
Interprets the top of the stack, i.e., st0 as a pointer p into
RAM.
Writes the stack’s n top-most values below st0, called , to RAM at the
address p+i, popping them.
Increments the RAM pointer, i.e., the top of the stack, by n.
1 ⩽ n ⩽ 5.
i | old stack | new stack | old RAM | new RAM |
|---|---|---|---|---|
1 | _ a p | _ p+1 | [] | [p: a] |
2 | _ b a p | _ p+2 | [] | [p: a, p+1: b] |
3 | _ c b a p | _ p+3 | [] | [p: a, p+1: b, p+2: c] |
4 | _ d c b a p | _ p+4 | [] | [p: a, p+1: b, p+2: c, p+3: d] |
5 | _ e d c b a p | _ p+5 | [] | [p: a, p+1: b, p+2: c, p+3: d, p+4: e] |
Hashing
hash
Opcode: 18
Hashes the stack’s ten top-most elements and puts the resulting digest onto the stack.
In more detail:
Pops the stack’s ten top-most elements, jihgfedcba.
The elements are reversed and one-padded to a length of 16, giving abcdefghij111111.
(This padding corresponds to the fixed-length input padding of Tip5;
see also section 2.5 of the Tip5 paper.)
The Tip5 permutation is applied to abcdefghij111111, resulting in αβγδεζηθικuvwxyz.
The first five elements of this result, i.e., αβγδε, are reversed and pushed onto the stack.
The new top of the stack is then εδγβα.
| old stack | new stack |
|---|---|
_ jihgfedcba | _ εδγβα |
assert_vector
Opcode: 26
Asserts equality of to for 0 ⩽ i ⩽ 4.
Crashes the VM if any pair is unequal.
Pops the 5 top-most stack elements.
| old stack | new stack |
|---|---|
_ edcba edcba | _ edcba |
sponge_init
Opcode: 40
Initializes (resets) the Sponge’s state. Must be the first Sponge instruction executed.
sponge_absorb
Opcode: 34
Absorbs the stack’s ten top-most elements into the Sponge state.
Crashes Triton VM if the Sponge state is not initialized.
| old stack | new stack |
|---|---|
_ jihgfedcba | _ |
sponge_absorb_mem
Opcode: 48
Absorbs the ten RAM elements at addresses p, p+1, … into the Sponge state.
Overwrites stack elements st1 through st4 with the first four absorbed elements.
Crashes Triton VM if the Sponge state is not initialized.
| old stack | new stack |
|---|---|
_ dcba p | _ hgfe (p+10) |
sponge_squeeze
Opcode: 56
Squeezes the Sponge and pushes the ten squeezed elements onto the stack.
Crashes Triton VM if the Sponge state is not initialized.
| old stack | new stack |
|---|---|
_ | _ zyxwvutsrq |
Base Field Arithmetic
add
Opcode: 42
Replaces the stack’s top two elements with their sum (as field elements).
| old stack | new stack |
|---|---|
_ b a | _ (a + b) |
addi + a
Opcode: 65
Adds the instruction’s argument a to the top of the stack.
| old stack | new stack |
|---|---|
_ b | _ (a + b) |
mul
Opcode: 50
Replaces the stack’s top two elements with their product (as field elements).
| old stack | new stack |
|---|---|
_ b a | _ (a·b) |
invert
Opcode: 64
Computes the multiplicative inverse (over the field) of the top of the stack. Crashes the VM if the top of the stack is 0.
| old stack | new stack |
|---|---|
_ a | _ (1/a) |
eq
Opcode: 58
Replaces the stack’s top two elements with 1 if they are equal, with 0 otherwise.
| old stack | new stack | |
|---|---|---|
a = b | _ b a | _ 1 |
a ≠ b | _ b a | _ 0 |
Bitwise Arithmetic
split
Opcode: 4
Decomposes the top of the stack into its lower 32 bits and its upper 32 bits. The lower 32 bits are the new top of the stack.
| old stack | new stack |
|---|---|
_ a | _ hi lo |
lt
Opcode: 6
“Less than” of the stack’s two top-most elements.
Crashes the VM if a or b is not u32.
| old stack | new stack |
|---|---|
_ b a | _ a<b |
and
Opcode: 14
Bitwise “and” of the stack’s two top-most elements.
Crashes the VM if a or b is not u32.
| old stack | new stack |
|---|---|
_ b a | _ a&b |
xor
Opcode: 22
Bitwise “exclusive or” of the stack’s two top-most elements.
Crashes the VM if a or b is not u32.
| old stack | new stack |
|---|---|
_ b a | _ a^b |
log_2_floor
Opcode: 12
The number of bits in a minus 1, i.e., .
Crashes the VM if a is 0 or not u32.
| old stack | new stack |
|---|---|
_ a | _ ⌊log₂(a)⌋ |
pow
Opcode: 30
The top of the stack to the power of the stack’s runner up.
Crashes the VM if exponent e is not u32.
| old stack | new stack |
|---|---|
_ e b | _ b**e |
div_mod
Opcode: 20
Division with remainder of numerator n by denominator d.
Guarantees the properties n == q·d + r and r < d.
Crashes the VM if n or d is not u32 or if d is 0.
| old stack | new stack |
|---|---|
_ d n | _ q r |
pop_count
Opcode: 28
Computes the hamming weight or “population count”
of the top of the stack, a.
Crashes the VM if a is not u32.
| old stack | new stack |
|---|---|
_ a | _ w |
Extension Field Arithmetic
xx_add
Opcode: 66
Replaces the top six elements of the stack with the sum of the two extension field elements encoded by the first and the second triple of stack elements.
| old stack | new stack |
|---|---|
_ z y x b c a | _ w v u |
xx_mul
Opcode: 74
Replaces the top six elements of the stack with the product of the two extension field elements encoded by the first and the second triple of stack elements.
| old stack | new stack |
|---|---|
_ z y x b c a | _ w v u |
x_invert
Opcode: 72
Inverts the extension field element encoded by field elements z y x in-place.
Crashes the VM if the extension field element is 0.
| old stack | new stack |
|---|---|
_ z y x | _ w v u |
xb_mul
Opcode: 82
Replaces the stack’s top four elements with the scalar product of the top of the stack with the
extension field element encoded by stack elements st1 through st3.
| old stack | new stack |
|---|---|
_ z y x a | _ w v u |
Input/Output
read_io + n
Opcode: 73
Reads n elements from standard input and pushes them onto the stack.
1 ⩽ n ⩽ 5.
n | old stack | new stack |
|---|---|---|
| 1 | _ | _ a |
| 2 | _ | _ b a |
| 3 | _ | _ c b a |
| 4 | _ | _ d c b a |
| 5 | _ | _ e d c b a |
write_io + n
Opcode: 19
Pops the top n elements from the stack and writes them to standard output.
1 ⩽ n ⩽ 5.
n | old stack | new stack |
|---|---|---|
| 1 | _ a | _ |
| 2 | _ b a | _ |
| 3 | _ c b a | _ |
| 4 | _ d c b a | _ |
| 5 | _ e d c b a | _ |
Many-In-One
merkle_step
Opcode: 36
Helps traversing a Merkle tree during authentication path verification.
The mechanics are as follows.
The 6th element of the stack i (also referred to as st5) is taken as the node index for a Merkle
tree that is claimed to include data whose digest is the content of stack registers st4 through
st0, i.e., edcba.
The sibling digest of edcba is εδγβα and is read from the
input interface of secret data.
The least-significant bit of i indicates whether edcba is the digest of a left leaf or a right
leaf of the Merkle tree’s current level.
Depending on this least significant bit of i, merkle_step either
- (
i= 0 mod 2) interpretsedcbaas the left digest,εδγβαas the right digest, or - (
i= 1 mod 2) interpretsεδγβαas the left digest,edcbaas the right digest.
In either case,
- the left and right digests are hashed, and the resulting digest
zyxwvreplaces the top of the stack, and - 6th register
iis shifted by 1 bit to the right, i.e., the least-significant bit is dropped.
In conjunction with instructions recurse_or_return and
assert_vector, instruction merkle_step and instruction
merkle_step_mem allow efficient verification of a Merkle authentication path.
Crashes the VM if i is not u32.
| old stack | new stack |
|---|---|
_ i edcba | _ (i div 2) zyxwv |
merkle_step_mem
Opcode: 44
Helps traversing a Merkle tree during authentication path verification with the authentication path being supplied in RAM.
This instruction works very similarly to instruction merkle_step.
The main difference, as the name suggests, is the source of the sibling digest:
Instead of reading it from the input interface of secret data, it is supplied via RAM.
Stack element st7 is taken as the RAM pointer, holding the memory address at which the next
sibling digest is located in RAM.
Executing instruction merkle_step_mem increments the memory pointer by the length of one digest,
anticipating an authentication path that is laid out continuously.
Stack element st6 does not change when executing instruction merkle_step_mem in order to
facilitate instruction recurse_or_return.
This instruction allows verifiable re-use of an authentication path. This is necessary, for example, when verifiably updating a Merkle tree: first, the authentication path is used to confirm inclusion of some old leaf, and then to compute the tree’s new root from the new leaf.
Crashes the VM if i is not u32.
| old stack | new stack |
|---|---|
_ p f i edcba | _ p+5 f (i div 2) zyxwv |
xx_dot_step
Opcode: 80
Reads two extension field elements from RAM located at the addresses corresponding to the two top
stack elements, multiplies the extension field elements, and adds the product (p0, p1, p2) to an
accumulator located on stack immediately below the two pointers.
Also, increases the pointers by the number of words read.
This instruction facilitates efficient computation of the dot product of two vectors containing extension field elements.
| old stack | new stack |
|---|---|
_ z y x *b *a | _ z+p2 y+p1 x+p0 *b+3 *a+3 |
xb_dot_step
Opcode: 88
Reads one base field element from RAM located at the addresses corresponding to the top of the
stack, one extension field element from RAM located at the address of the second stack element,
multiplies the field elements, and adds the product (p0, p1, p2) to an accumulator located on
stack immediately below the two pointers.
Also, increase the pointers by the number of words read.
This instruction facilitates efficient computation of the dot product of a vector containing base field elements with a vector containing extension field elements.
| old stack | new stack |
|---|---|
_ z y x *b *a | _ z+p2 y+p1 x+p0 *b+3 *a+1 |
Arithmetization
An arithmetization defines two things:
- algebraic execution tables (AETs), and
- arithmetic intermediate representation (AIR) constraints.
For Triton VM, the execution trace is spread over multiple tables.
These tables are linked by various cryptographic arguments.
This division allows for a separation of concerns.
For example, the main processor’s trace is recorded in the Processor Table.
The main processor can delegate the execution of somewhat-difficult-to-arithmetize instructions like hash or xor to a co-processor.
The arithmetization of the co-processor is largely independent from the main processor and recorded in its separate trace.
For example, instructions relating to hashing are executed by the hash co-processor.
Its trace is recorded in the Hash Table.
Similarly, bitwise instructions are executed by the u32 co-processor, and the corresponding trace recorded in the U32 Table.
Another example for the separation of concerns is memory consistency, the bulk of which is delegated to the Operational Stack Table, RAM Table, and Jump Stack Table.
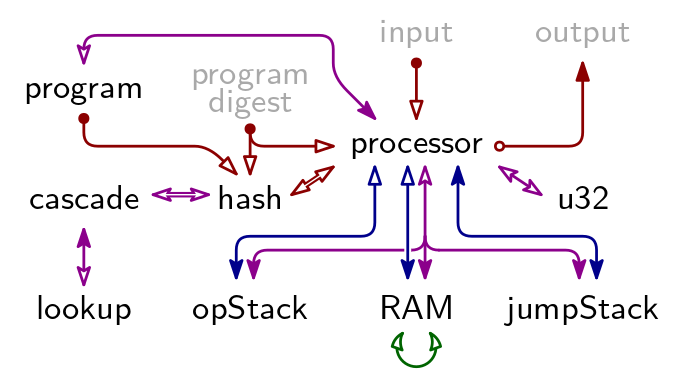
Algebraic Execution Tables
There are 9 Arithmetic Execution Tables in TritonVM. Their relation is described by below figure. A a blue arrow indicates a Permutation Argument, a red arrow indicates an Evaluation Argument, a purple arrow indicates a Lookup Argument, and the green arrow is the Contiguity Argument.
The grayed-out elements “program digest”, “input”, and “output” are not AETs but publicly available information. Together, they constitute the claim for which Triton VM produces a proof. See “Arguments Using Public Information” and “Program Attestation” for the Evaluation Arguments with which they are linked into the rest of the proof system.
Main Tables
The values of all registers, and consequently the elements on the stack, in memory, and so on, are elements of the B-field, i.e., where is the Oxfoi prime, . All values of columns corresponding to one such register are elements of the B-Field as well. Together, these columns are referred to as table’s main columns, and make up the main table.
Auxiliary Tables
The entries of a table’s columns corresponding to Permutation, Evaluation, and Lookup Arguments are elements from the X-field . These columns are referred to as a table’s auxiliary columns, both because the entries are elements of the X-field and because the entries can only be computed using the main tables, through an auxiliary process. Together, these columns are referred to as a table’s auxiliary columns, and make up the auxiliary table.
Padding
For reasons of computational efficiency, it is beneficial that an Algebraic Execution Table’s height equals a power of 2. To this end, tables are padded. The height of the longest AET determines the padded height for all tables, which is .
Arithmetic Intermediate Representation
For each table, up to four lists containing constraints of different type are given:
- Initial Constraints, defining values in a table’s first row,
- Consistency Constraints, establishing consistency within any given row,
- Transition Constraints, establishing the consistency of two consecutive rows in relation to each other, and
- Terminal Constraints, defining values in a table’s last row.
Together, all these constraints constitute the AIR constraints.
Arguments Using Public Information
Triton VM uses a number of public arguments. That is, one side of the link can be computed by the verifier using publicly available information; the other side of the link is verified through one or more AIR constraints.
The two most prominent instances of this are public input and output: both are given to the verifier explicitly. The verifier can compute the terminal of an Evaluation Argument using public input (respectively, output). In the Processor Table, AIR constraints guarantee that the used input (respectively, output) symbols are accumulated similarly. Comparing the two terminal values establishes that use of public input (respectively, production of public output) was integral.
The third public argument establishes correctness of the Lookup Table, and is explained there. The fourth public argument relates to program attestation, and is also explained on its corresponding page.
Arithmetization Overview
Tables
| table name | #main cols | #aux cols | total width |
|---|---|---|---|
| ProgramTable | 7 | 3 | 16 |
| ProcessorTable | 39 | 11 | 72 |
| OpStackTable | 4 | 2 | 10 |
| RamTable | 7 | 6 | 25 |
| JumpStackTable | 5 | 2 | 11 |
| HashTable | 67 | 20 | 127 |
| CascadeTable | 6 | 2 | 12 |
| LookupTable | 4 | 2 | 10 |
| U32Table | 10 | 1 | 13 |
| DegreeLowering (-/8/4) | 0/118/230 | 0/14/38 | 0/160/344 |
| Randomizers | 0 | 1 | 3 |
| TOTAL | 149/267/379 | 50/64/88 | 299/459/643 |
Constraints
The following table captures the state of affairs in terms of constraints before automatic degree lowering. In particular, automatic degree lowering introduces new columns, modifies the constraint set (in a way that is equivalent to what was there before), and lowers the constraints’ maximal degree.
Before automatic degree lowering:
| table name | #initial | #consistency | #transition | #terminal | max degree |
|---|---|---|---|---|---|
| ProgramTable | 6 | 4 | 10 | 2 | 4 |
| ProcessorTable | 29 | 10 | 41 | 1 | 19 |
| OpStackTable | 3 | 0 | 5 | 0 | 4 |
| RamTable | 7 | 0 | 12 | 1 | 5 |
| JumpStackTable | 6 | 0 | 6 | 0 | 5 |
| HashTable | 22 | 45 | 47 | 2 | 9 |
| CascadeTable | 2 | 1 | 3 | 0 | 4 |
| LookupTable | 3 | 1 | 4 | 1 | 3 |
| U32Table | 1 | 15 | 22 | 2 | 12 |
| Grand Cross-Table Argument | 0 | 0 | 0 | 14 | 1 |
| TOTAL | 79 | 76 | 150 | 23 | 19 |
| (# nodes) | (534) | (624) | (6679) | (213) |
After lowering degree to 8:
| table name | #initial | #consistency | #transition | #terminal |
|---|---|---|---|---|
| ProgramTable | 6 | 4 | 10 | 2 |
| ProcessorTable | 29 | 10 | 165 | 1 |
| OpStackTable | 3 | 0 | 5 | 0 |
| RamTable | 7 | 0 | 12 | 1 |
| JumpStackTable | 6 | 0 | 6 | 0 |
| HashTable | 22 | 46 | 49 | 2 |
| CascadeTable | 2 | 1 | 3 | 0 |
| LookupTable | 3 | 1 | 4 | 1 |
| U32Table | 1 | 18 | 24 | 2 |
| Grand Cross-Table Argument | 0 | 0 | 0 | 14 |
| TOTAL | 79 | 80 | 278 | 23 |
| (# nodes) | (534) | (635) | (6956) | (213) |
After lowering degree to 4:
| table name | #initial | #consistency | #transition | #terminal |
|---|---|---|---|---|
| ProgramTable | 6 | 4 | 10 | 2 |
| ProcessorTable | 31 | 10 | 238 | 1 |
| OpStackTable | 3 | 0 | 5 | 0 |
| RamTable | 7 | 0 | 13 | 1 |
| JumpStackTable | 6 | 0 | 7 | 0 |
| HashTable | 22 | 52 | 84 | 2 |
| CascadeTable | 2 | 1 | 3 | 0 |
| LookupTable | 3 | 1 | 4 | 1 |
| U32Table | 1 | 26 | 34 | 2 |
| Grand Cross-Table Argument | 0 | 0 | 0 | 14 |
| TOTAL | 81 | 94 | 398 | 23 |
| (# nodes) | (538) | (676) | (7246) | (213) |
Triton Assembly Constraint Evaluation
Triton VM’s recursive verifier needs to evaluate Triton VM’s AIR constraints. In order to gauge the runtime cost for this step, the following table provides estimates for that step’s contribution to various tables.
| Type | Processor | Op Stack | RAM |
|---|---|---|---|
| static | 33346 | 61505 | 24555 |
| dynamic | 44731 | 69099 | 28350 |
Opcode Pressure
When changing existing or introducing new instructions, one consideration is: how many other instructions compete for opcodes in the same instruction category? The table below helps answer this question at a glance.
| IsU32 | ShrinksStack | HasArg | Num Opcodes |
|---|---|---|---|
| n | n | n | 12 |
| n | n | y | 10 |
| n | y | n | 11 |
| n | y | y | 3 |
| y | n | n | 6 |
| y | n | y | 0 |
| y | y | n | 4 |
| y | y | y | 0 |
Maximum number of opcodes per row is 16.
Program Table
The Program Table contains the entire program as a read-only list of instruction opcodes and their arguments.
The processor looks up instructions and arguments using its instruction pointer ip.
For program attestation, the program is padded and sent to the Hash Table in chunks of size 10, which is the of the Tip5 hash function. Program padding is one 1 followed by the minimal number of 0’s necessary to make the padded input length a multiple of the 1.
Main Columns
The Program Table consists of 7 main columns. Those columns marked with an asterisk (*) are only used for program attestation.
| Column | Description |
|---|---|
Address | an instruction’s address |
Instruction | the (opcode of the) instruction |
LookupMultiplicity | how often an instruction has been executed |
*IndexInChunk | Address modulo the Tip5 , which is 10 |
*MaxMinusIndexInChunkInv | the inverse-or-zero of |
*IsHashInputPadding | padding indicator for absorbing the program into the Sponge |
IsTablePadding | padding indicator for rows only required due to the dominating length of some other table |
Auxiliary Columns
A Lookup Argument with the Processor Table establishes that the processor has loaded the correct instruction (and its argument) from program memory.
To establish the program memory’s side of the Lookup Argument, the Program Table has auxiliary column InstructionLookupServerLogDerivative.
For sending the padded program to the Hash Table, a combination of two Evaluation Arguments is used.
The first, PrepareChunkRunningEvaluation, absorbs one chunk of (i.e. 10) instructions at a time, after which it is reset and starts absorbing again.
The second, SendChunkRunningEvaluation, absorbs one such prepared chunk every 10 instructions.
Padding
A padding row is a copy of the Program Table’s last row with the following modifications:
- column
Addressis increased by 1, - column
Instructionis set to 0, - column
LookupMultiplicityis set to 0, - column
IndexInChunkis set toAddressmod , - column
MaxMinusIndexInChunkInvis set to the inverse-or-zero of , - column
IsHashInputPaddingis set to 1, and - column
IsTablePaddingis set to 1.
Above procedure is iterated until the necessary number of rows have been added.
A Note on the Instruction Lookup Argument
For almost all table-linking arguments, the initial row contains the argument’s initial value after having applied the first update. For example, the initial row for a Lookup Argument usually contains for some and . As an exception, the Program Table’s instruction Lookup Argument always records 0 in the initial row.
Recall that the Lookup Argument is not just about the instruction, but also about the instruction’s argument if it has one, or the next instruction if it has none. In the Program Table, this argument (or the next instruction) is recorded in the next row from the instruction in question. Therefore, verifying correct application of the logarithmic derivative’s update rule requires access to both the current and the next row.
Out of all constraint types, only Transition Constraints have access to more than one row at a time. This implies that the correct application of the first update of the instruction Lookup Argument cannot be verified by an initial constraint. Therefore, the recorded initial value must be independent of the second row.
Consequently, the final value for the Lookup Argument is recorded in the first row just after the program description ends. This row is guaranteed to exist because of the mechanics for program attestation: the program has to be padded with at least one 1 before it is hashed.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- The
Addressis 0. - The
IndexInChunkis 0. - The indicator
IsHashInputPaddingis 0. - The
InstructionLookupServerLogDerivativeis 0. PrepareChunkRunningEvaluationhas absorbedInstructionwith respect to challenge 🪑.SendChunkRunningEvaluationis 1.
Initial Constraints as Polynomials
AddressIndexInChunkIsHashInputPaddingInstructionLookupServerLogDerivativePrepareChunkRunningEvaluation - 🪑 - InstructionSendChunkRunningEvaluation - 1
Consistency Constraints
- The
MaxMinusIndexInChunkInvis zero or the inverse ofIndexInChunk. - The
IndexInChunkis or theMaxMinusIndexInChunkInvis the inverse ofIndexInChunk. - Indicator
IsHashInputPaddingis either 0 or 1. - Indicator
IsTablePaddingis either 0 or 1.
Consistency Constraints as Polynomials
(1 - MaxMinusIndexInChunkInv · (rate - 1 - IndexInChunk)) · MaxMinusIndexInChunkInv(1 - MaxMinusIndexInChunkInv · (rate - 1 - IndexInChunk)) · (rate - 1 - IndexInChunk)IsHashInputPadding · (IsHashInputPadding - 1)IsTablePadding · (IsTablePadding - 1)
Transition Constraints
- The
Addressincreases by 1. - If the
IndexInChunkis not , it increases by 1. Else, theIndexInChunkin the next row is 0. - The indicator
IsHashInputPaddingis 0 or remains unchanged. - The padding indicator
IsTablePaddingis 0 or remains unchanged. - If
IsHashInputPaddingis 0 in the current row and 1 in the next row, thenInstructionin the next row is 1. - If
IsHashInputPaddingis 1 in the current row thenInstructionin the next row is 0. - If
IsHashInputPaddingis 1 in the current row andIndexInChunkis in the current row thenIsTablePaddingis 1 in the next row. - If the current row is not a padding row, the logarithmic derivative accumulates the current row’s address, the current row’s instruction, and the next row’s instruction with respect to challenges 🥝, 🥥, and 🫐 and indeterminate 🪥 respectively. Otherwise, it remains unchanged.
- If the
IndexInChunkin the current row is not , thenPrepareChunkRunningEvaluationabsorbs theInstructionin the next row with respect to challenge 🪑. Otherwise,PrepareChunkRunningEvaluationresets and absorbs theInstructionin the next row with respect to challenge 🪑. - If the next row is not a padding row and the
IndexInChunkin the next row is , thenSendChunkRunningEvaluationabsorbsPrepareChunkRunningEvaluationin the next row with respect to variable 🪣. Otherwise, it remains unchanged.
Transition Constraints as Polynomials
Address' - Address - 1MaxMinusIndexInChunkInv · (IndexInChunk' - IndexInChunk - 1)
+ (1 - MaxMinusIndexInChunkInv · (rate - 1 - IndexInChunk)) · IndexInChunk'IsHashInputPadding · (IsHashInputPadding' - IsHashInputPadding)IsTablePadding · (IsTablePadding' - IsTablePadding)(IsHashInputPadding - 1) · IsHashInputPadding' · (Instruction' - 1)IsHashInputPadding · Instruction'IsHashInputPadding · (1 - MaxMinusIndexInChunkInv · (rate - 1 - IndexInChunk)) · IsTablePadding'(1 - IsHashInputPadding) · ((InstructionLookupServerLogDerivative' - InstructionLookupServerLogDerivative) · (🪥 - 🥝·Address - 🥥·Instruction - 🫐·Instruction') - LookupMultiplicity)
+ IsHashInputPadding · (InstructionLookupServerLogDerivative' - InstructionLookupServerLogDerivative)(rate - 1 - IndexInChunk) · (PrepareChunkRunningEvaluation' - 🪑·PrepareChunkRunningEvaluation - Instruction')
+ (1 - MaxMinusIndexInChunkInv · (rate - 1 - IndexInChunk)) · (PrepareChunkRunningEvaluation' - 🪑 - Instruction')(IsTablePadding' - 1) · (1 - MaxMinusIndexInChunkInv' · (rate - 1 - IndexInChunk')) · (SendChunkRunningEvaluation' - 🪣·SendChunkRunningEvaluation - PrepareChunkRunningEvaluation')
+ (SendChunkRunningEvaluation' - SendChunkRunningEvaluation) · IsTablePadding'
+ (SendChunkRunningEvaluation' - SendChunkRunningEvaluation) · (rate - 1 - IndexInChunk')
Terminal Constraints
- The indicator
IsHashInputPaddingis 1. - The
IndexInChunkis or the indicatorIsTablePaddingis 1.
Terminal Constraints as Polynomials
IsHashInputPadding - 1(rate - 1 - IndexInChunk) · (IsTablePadding - 1)
-
See also section 2.5 “Fixed-Length versus Variable-Length” in the Tip5 paper. ↩
Processor Table
The Processor Table records all of Triton VM states during execution of a particular program.
The states are recorded in chronological order.
The first row is the initial state, the last (non-padding) row is the terminal state, i.e., the state after having executed instruction halt.
It is impossible to generate a valid proof if the instruction executed last is anything but halt.
It is worth highlighting the initialization of the operational stack.
Stack elements st0 through st10 are initially 0.
However, stack elements st11 through st15, i.e., the very bottom of the stack, are initialized with the hash digest of the program that is being executed.
This is primarily useful for recursive verifiers:
they can compare their own program digest to the program digest of the proof they are verifying.
This way, a recursive verifier can easily determine if they are actually recursing, or whether the proof they are checking was generated using an entirely different program.
A more detailed explanation of the mechanics can be found on the page about program attestation.
Main Columns
The processor consists of all registers defined in the Instruction Set Architecture. Each register is assigned a column in the processor table.
Auxiliary Columns
The Processor Table has the following auxiliary columns, corresponding to Evaluation Arguments, Permutation Arguments, and Lookup Arguments:
RunningEvaluationStandardInputfor the Evaluation Argument with the input symbols.RunningEvaluationStandardOutputfor the Evaluation Argument with the output symbols.InstructionLookupClientLogDerivativefor the Lookup Argument with the Program TableRunningProductOpStackTablefor the Permutation Argument with the Op Stack Table.RunningProductRamTablefor the Permutation Argument with the RAM Table. Note that virtual columninstruction_typeholds value 1 for reads and 0 for writes.RunningProductJumpStackTablefor the Permutation Argument with the Jump Stack Table.RunningEvaluationHashInputfor the Evaluation Argument with the Hash Table for copying the input to the hash function from the processor to the hash coprocessor.RunningEvaluationHashDigestfor the Evaluation Argument with the Hash Table for copying the hash digest from the hash coprocessor to the processor.RunningEvaluationSpongefor the Evaluation Argument with the Hash Table for copying the 10 next to-be-absorbed elements from the processor to the hash coprocessor or the 10 next squeezed elements from the hash coprocessor to the processor, depending on the instruction.U32LookupClientLogDerivativefor the Lookup Argument with the U32 Table.ClockJumpDifferenceLookupServerLogDerivativefor the Lookup Argument of clock jump differences with the Op Stack Table, the RAM Table, and the Jump Stack Table.
Permutation Argument with the Op Stack Table
The subset Permutation Argument with the Op Stack Table RunningProductOpStackTable establishes consistency of the op stack underflow memory.
The number of factors incorporated into the running product at any given cycle depends on the executed instruction in this cycle:
for every element pushed to or popped from the stack, there is one factor.
Namely, if the op stack grows, every element spilling from st15 into op stack underflow memory will be incorporated as one factor;
and if the op stack shrinks, every element from op stack underflow memory being transferred into st15 will be one factor.
Notably, if an instruction shrinks the op stack by more than one element in a single clock cycle, each spilled element is incorporated as one factor. The same holds true for instructions growing the op stack by more than one element in a single clock cycle.
One key insight for this Permutation Argument is that the processor will always have access to the elements that are to be read from or written to underflow memory:
if the instruction grows the op stack, then the elements in question currently reside in the directly accessible, top part of the stack;
if the instruction shrinks the op stack, then the elements in question will be in the top part of the stack in the next cycle.
In either case, the Transition Constraint for the Permutation Argument can incorporate the explicitly listed elements as well as the corresponding trivial-to-compute op_stack_pointer.
Padding
A padding row is a copy of the Processor Table’s last row with the following modifications:
- column
clkis increased by 1, - column
IsPaddingis set to 1, - column
cjd_mulis set to 0,
A notable exception:
if the row with clk equal to 1 is a padding row, then the value of cjd_mul is not constrained in that row.
The reason for this exception is the lack of “awareness” of padding rows in the Jump Stack Table:
it keeps looking up clock jump differences in its padding section.
All these clock jumps are guaranteed to have magnitude 1.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Note, that the transition constraint’s use of some_column vs some_column_next might be a little unintuitive.
For example, take the following part of some execution trace.
| Clock Cycle | Current Instruction | st0 | … | st15 | Running Evaluation “To Hash Table” | Running Evaluation “From Hash Table” |
|---|---|---|---|---|---|---|
foo | 17 | … | 22 | |||
| hash | 17 | … | 22 | |||
bar | 1337 | … | 22 |
In order to verify the correctness of RunningEvaluationHashInput, the corresponding transition constraint needs to conditionally “activate” on row-tuple (, ), where it is conditional on ci_next (not ci), and verifies absorption of the next row, i.e., row .
However, in order to verify the correctness of RunningEvaluationHashDigest, the corresponding transition constraint needs to conditionally “activate” on row-tuple (, ), where it is conditional on ci (not ci_next), and verifies absorption of the next row, i.e., row .
Initial Constraints
- The cycle counter
clkis 0. - The instruction pointer
ipis 0. - The jump address stack pointer
jspis 0. - The jump address origin
jsois 0. - The jump address destination
jsdis 0. - The operational stack element
st0is 0. - The operational stack element
st1is 0. - The operational stack element
st2is 0. - The operational stack element
st3is 0. - The operational stack element
st4is 0. - The operational stack element
st5is 0. - The operational stack element
st6is 0. - The operational stack element
st7is 0. - The operational stack element
st8is 0. - The operational stack element
st9is 0. - The operational stack element
st10is 0. - The Evaluation Argument of operational stack elements
st11throughst15with respect to indeterminate 🥬 equals the public part of program digest challenge, 🫑. See program attestation for more details. - The
op_stack_pointeris 16. RunningEvaluationStandardInputis 1.RunningEvaluationStandardOutputis 1.InstructionLookupClientLogDerivativehas absorbed the first row with respect to challenges 🥝, 🥥, and 🫐 and indeterminate 🪥.RunningProductOpStackTableis 1.RunningProductRamTablehas absorbed the first row with respect to challenges 🍍, 🍈, 🍎, and 🌽 and indeterminate 🛋.RunningProductJumpStackTablehas absorbed the first row with respect to challenges 🍇, 🍅, 🍌, 🍏, and 🍐 and indeterminate 🧴.RunningEvaluationHashInputhas absorbed the first row with respect to challenges 🧄₀ through 🧄₉ and indeterminate 🚪 if the current instruction ishash. Otherwise, it is 1.RunningEvaluationHashDigestis 1.RunningEvaluationSpongeis 1.U32LookupClientLogDerivativeis 0.ClockJumpDifferenceLookupServerLogDerivativestarts having accumulated the first contribution.
Consistency Constraints
- The composition of instruction bits
ib0throughib6corresponds to the current instructionci. - The instruction bit
ib0is a bit. - The instruction bit
ib1is a bit. - The instruction bit
ib2is a bit. - The instruction bit
ib3is a bit. - The instruction bit
ib4is a bit. - The instruction bit
ib5is a bit. - The instruction bit
ib6is a bit. - The padding indicator
IsPaddingis either 0 or 1. - If the current padding row is a padding row and
clkis not 1, then the clock jump difference lookup multiplicity is 0.
Transition Constraints
Due to their complexity, instruction-specific constraints are defined in their own section. The following additional constraints also apply to every pair of rows.
- The cycle counter
clkincreases by 1. - The padding indicator
IsPaddingis 0 or remains unchanged. - If the next row is not a padding row, the logarithmic derivative for the Program Table absorbs the next row with respect to challenges 🥝, 🥥, and 🫐 and indeterminate 🪥. Otherwise, it remains unchanged.
- The running sum for the logarithmic derivative of the clock jump difference lookup argument accumulates the next row’s
clkwith the appropriate multiplicitycjd_mulwith respect to indeterminate 🪞. - The running product for the Jump Stack Table absorbs the next row with respect to challenges 🍇, 🍅, 🍌, 🍏, and 🍐 and indeterminate 🧴.
-
- If the current instruction in the next row is
hash, the running evaluation “Hash Input” absorbs the next row with respect to challenges 🧄₀ through 🧄₉ and indeterminate 🚪. - If the current instruction in the next row is
merkle_stepormerkle_step_memand helper variablehv5…- …is 0, the running evaluation “Hash Input” absorbs next row’s
st0throughst4andhv0throughhv4… - …is 1, the running evaluation “Hash Input” absorbs next row’s
hv0throughhv4andst0throughst4…
…with respect to challenges 🧄₀ through 🧄₉ and indeterminate 🚪.
- …is 0, the running evaluation “Hash Input” absorbs next row’s
- Otherwise, it remains unchanged.
- If the current instruction in the next row is
- If the current instruction is
hash,merkle_step, ormerkle_step_mem, the running evaluation “Hash Digest” absorbs the next row with respect to challenges 🧄₀ through 🧄₄ and indeterminate 🪟. Otherwise, it remains unchanged. - If the current instruction is
sponge_init, then the running evaluation “Sponge” absorbs the current instruction and the Sponge’s default initial state with respect to challenges 🧅 and 🧄₀ through 🧄₉ and indeterminate 🧽. Else if the current instruction issponge_absorb, then the running evaluation “Sponge” absorbs the current instruction and the current row with respect to challenges 🧅 and 🧄₀ through 🧄₉ and indeterminate 🧽. Else if the current instruction issponge_squeeze, then the running evaluation “Sponge” absorbs the current instruction and the next row with respect to challenges 🧅 and 🧄₀ through 🧄₉ and indeterminate 🧽. Else if the current instruction issponge_absorb_mem, then the running evaluation “Sponge” absorbs the opcode of instructionsponge_absorband stack elementsst1throughst4and all 6 helper variables with respect to challenges 🧅 and 🧄₀ through 🧄₉ and indeterminate 🧽. Otherwise, the running evaluation remains unchanged. -
- If the current instruction is
split, then the logarithmic derivative for the Lookup Argument with the U32 Table accumulatesst0andst1in the next row andciin the current row with respect to challenges 🥜, 🌰, and 🥑, and indeterminate 🧷. - If the current instruction is
lt,and,xor, orpow, then the logarithmic derivative for the Lookup Argument with the U32 Table accumulatesst0,st1, andciin the current row andst0in the next row with respect to challenges 🥜, 🌰, 🥑, and 🥕, and indeterminate 🧷. - If the current instruction is
log_2_floor, then the logarithmic derivative for the Lookup Argument with the U32 Table accumulatesst0andciin the current row andst0in the next row with respect to challenges 🥜, 🥑, and 🥕, and indeterminate 🧷. - If the current instruction is
div_mod, then the logarithmic derivative for the Lookup Argument with the U32 Table accumulates bothst0in the next row andst1in the current row as well as the constantsopcode(lt)and1with respect to challenges 🥜, 🌰, 🥑, and 🥕, and indeterminate 🧷.st0in the current row andst1in the next row as well asopcode(split)with respect to challenges 🥜, 🌰, and 🥑, and indeterminate 🧷.
- If the current instruction is
merkle_stepormerkle_step_mem, then the logarithmic derivative for the Lookup Argument with the U32 Table accumulatesst5from the current and next rows as well asopcode(split)with respect to challenges 🥜, 🌰, and 🥑, and indeterminate 🧷. - If the current instruction is
pop_count, then the logarithmic derivative for the Lookup Argument with the U32 Table accumulatesst0andciin the current row andst0in the next row with respect to challenges 🥜, 🥑, and 🥕, and indeterminate 🧷. - Else, i.e., if the current instruction is not a u32 instruction, the logarithmic derivative for the Lookup Argument with the U32 Table remains unchanged.
- If the current instruction is
Terminal Constraints
- In the last row, register “current instruction”
ciis 0, corresponding to instructionhalt.
Instruction Groups
Some transition constraints are shared across some, or even many instructions.
For example, most instructions must not change the jump stack.
Likewise, most instructions must not change RAM.
To simplify presentation of the instruction-specific transition constraints, these common constraints are grouped together and aliased.
Continuing above example, instruction group keep_jump_stack contains all transition constraints to ensure that the jump stack remains unchanged.
The next section treats each instruction group in detail. The following table lists and briefly explains all instruction groups.
| group name | description |
|---|---|
decompose_arg | instruction’s argument held in nia is binary decomposed into helper registers hv0 through hv3 |
prohibit_illegal_num_words | constrain the instruction’s argument n to 1 ⩽ n ⩽ 5 |
no_io | the running evaluations for public input & output remain unchanged |
no_ram | RAM is not being accessed, i.e., the running product of the Permutation Argument with the RAM Table remains unchanged |
keep_jump_stack | jump stack does not change, i.e., registers jsp, jso, and jsd do not change |
step_1 | jump stack does not change and instruction pointer ip increases by 1 |
step_2 | jump stack does not change and instruction pointer ip increases by 2 |
grow_op_stack | op stack elements are shifted down by one position, top element of the resulting stack is unconstrained |
grow_op_stack_by_any_of | op stack elements are shifted down by n positions, top n elements of the resulting stack are unconstrained, where n is the instruction’s argument |
keep_op_stack_height | the op stack height remains unchanged, and so in particular the running product of the Permutation Argument with the Op Stack table remains unchanged |
op_stack_remains_except_top_n | all but the top n elements of the op stack remain unchanged |
keep_op_stack | op stack remains entirely unchanged |
binary_operation | op stack elements starting from st2 are shifted up by one position, highest two elements of the resulting stack are unconstrained |
shrink_op_stack | op stack elements starting from st1 are shifted up by one position |
shrink_op_stack_by_any_of | op stack elements starting from stn are shifted up by one position, where n is the instruction’s argument |
The following instruction groups conceptually fit the category of ‘instruction groups’ but are not used or enforced through AIR constraints.
| group name | description |
|---|---|
no_hash | The hash coprocessor is not accessed. The constraints are implied by the evaluation argument with the Hash Table which takes the current instruction into account. |
A summary of all instructions and which groups they are part of is given in the following table.
| instruction | decompose_arg | prohibit_illegal_num_words | no_io | no_ram | keep_jump_stack | step_1 | step_2 | grow_op_stack | grow_op_stack_by_any_of | keep_op_stack_height | op_stack_remains_except_top_n | keep_op_stack | binary_operation | shrink_op_stack | shrink_op_stack_by_any_of |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
push + a | x | x | x | x | |||||||||||
pop + n | x | x | x | x | x | x | |||||||||
divine + n | x | x | x | x | x | x | |||||||||
pick + i | x | x | x | x | x | ||||||||||
place + i | x | x | x | x | x | ||||||||||
dup + i | x | x | x | x | x | ||||||||||
swap + i | x | x | x | x | x | ||||||||||
nop | x | x | x | x | 0 | x | |||||||||
skiz | x | x | x | x | |||||||||||
call + d | x | x | x | 0 | x | ||||||||||
return | x | x | x | 0 | x | ||||||||||
recurse | x | x | x | x | 0 | x | |||||||||
recurse_or_return | x | x | x | 0 | x | ||||||||||
assert | x | x | x | x | |||||||||||
halt | x | x | x | x | 0 | x | |||||||||
read_mem + n | x | x | x | x | |||||||||||
write_mem + n | x | x | x | x | |||||||||||
hash | x | x | x | ||||||||||||
assert_vector | x | x | x | ||||||||||||
sponge_init | x | x | x | ||||||||||||
sponge_absorb | x | x | x | ||||||||||||
sponge_absorb_mem | x | x | 5 | ||||||||||||
sponge_squeeze | x | x | x | ||||||||||||
add | x | x | x | ||||||||||||
addi + a | x | x | x | x | 1 | ||||||||||
mul | x | x | x | x | |||||||||||
invert | x | x | x | x | 1 | ||||||||||
eq | x | x | x | x | |||||||||||
split | x | x | x | ||||||||||||
lt | x | x | x | x | |||||||||||
and | x | x | x | x | |||||||||||
xor | x | x | x | x | |||||||||||
log_2_floor | x | x | x | x | 1 | ||||||||||
pow | x | x | x | x | |||||||||||
div_mod | x | x | x | x | 2 | ||||||||||
pop_count | x | x | x | x | 1 | ||||||||||
xx_add | x | x | x | ||||||||||||
xx_mul | x | x | x | ||||||||||||
x_invert | x | x | x | x | 3 | ||||||||||
xb_mul | x | x | x | ||||||||||||
read_io + n | x | x | x | x | x | ||||||||||
write_io + n | x | x | x | x | x | ||||||||||
merkle_step | x | x | x | 6 | |||||||||||
merkle_step_mem | x | x | 8 | ||||||||||||
xx_dot_step | x | x | 5 | ||||||||||||
xb_dot_step | x | x | 5 | x |
Indicator Polynomials ind_i(hv3, hv2, hv1, hv0)
In this and the following sections, a register marked with a ' refers to the next state of that register.
For example, st0' = st0 + 2 means that stack register st0 is incremented by 2.
An alternative view for the same concept is that registers marked with ' are those of the next row in the table.
For instructions like dup i, swap i, pop n, et cetera, it is beneficial to have polynomials that evaluate to 1 if the instruction’s argument is a specific value, and to 0 otherwise.
This allows indicating which registers are constraint, and in which way they are, depending on the argument.
This is the purpose of the indicator polynomials ind_i.
Evaluated on the binary decomposition of i, they show the behavior described above.
For example, take i = 13.
The corresponding binary decomposition is (hv3, hv2, hv1, hv0) = (1, 1, 0, 1).
Indicator polynomial ind_13(hv3, hv2, hv1, hv0) is defined as hv3·hv2·(1 - hv1)·hv0.
It evaluates to 1 on (1, 1, 0, 1), i.e., ind_13(1, 1, 0, 1) = 1.
Any other indicator polynomial, like ind_7, evaluates to 0 on (1, 1, 0, 1).
Likewise, the indicator polynomial for 13 evaluates to 0 for any other argument.
The list of all 16 indicator polynomials is:
ind_0(hv3, hv2, hv1, hv0) = (1 - hv3)·(1 - hv2)·(1 - hv1)·(1 - hv0)ind_1(hv3, hv2, hv1, hv0) = (1 - hv3)·(1 - hv2)·(1 - hv1)·hv0ind_2(hv3, hv2, hv1, hv0) = (1 - hv3)·(1 - hv2)·hv1·(1 - hv0)ind_3(hv3, hv2, hv1, hv0) = (1 - hv3)·(1 - hv2)·hv1·hv0ind_4(hv3, hv2, hv1, hv0) = (1 - hv3)·hv2·(1 - hv1)·(1 - hv0)ind_5(hv3, hv2, hv1, hv0) = (1 - hv3)·hv2·(1 - hv1)·hv0ind_6(hv3, hv2, hv1, hv0) = (1 - hv3)·hv2·hv1·(1 - hv0)ind_7(hv3, hv2, hv1, hv0) = (1 - hv3)·hv2·hv1·hv0ind_8(hv3, hv2, hv1, hv0) = hv3·(1 - hv2)·(1 - hv1)·(1 - hv0)ind_9(hv3, hv2, hv1, hv0) = hv3·(1 - hv2)·(1 - hv1)·hv0ind_10(hv3, hv2, hv1, hv0) = hv3·(1 - hv2)·hv1·(1 - hv0)ind_11(hv3, hv2, hv1, hv0) = hv3·(1 - hv2)·hv1·hv0ind_12(hv3, hv2, hv1, hv0) = hv3·hv2·(1 - hv1)·(1 - hv0)ind_13(hv3, hv2, hv1, hv0) = hv3·hv2·(1 - hv1)·hv0ind_14(hv3, hv2, hv1, hv0) = hv3·hv2·hv1·(1 - hv0)ind_15(hv3, hv2, hv1, hv0) = hv3·hv2·hv1·hv0
Group decompose_arg
Description
- The helper variables
hv0throughhv3are the binary decomposition of the instruction’s argument, which is held in registernia. - The helper variable
hv0is either 0 or 1. - The helper variable
hv1is either 0 or 1. - The helper variable
hv2is either 0 or 1. - The helper variable
hv3is either 0 or 1.
Polynomials
nia - (8·hv3 + 4·hv2 + 2·hv1 + hv0)hv0·(hv0 - 1)hv1·(hv1 - 1)hv2·(hv2 - 1)hv3·(hv3 - 1)
Group prohibit_illegal_num_words
Is only ever used in combination with instruction group decompose_arg.
Therefore, the instruction argument’s correct binary decomposition is known to be in helper variables hv0 through hv3.
Description
- The argument is not 0.
- The argument is not 6.
- The argument is not 7.
- The argument is not 8.
- The argument is not 9.
- The argument is not 10.
- The argument is not 11.
- The argument is not 12.
- The argument is not 13.
- The argument is not 14.
- The argument is not 15.
Polynomials
ind_0(hv3, hv2, hv1, hv0)ind_6(hv3, hv2, hv1, hv0)ind_7(hv3, hv2, hv1, hv0)ind_8(hv3, hv2, hv1, hv0)ind_9(hv3, hv2, hv1, hv0)ind_10(hv3, hv2, hv1, hv0)ind_11(hv3, hv2, hv1, hv0)ind_12(hv3, hv2, hv1, hv0)ind_13(hv3, hv2, hv1, hv0)ind_14(hv3, hv2, hv1, hv0)ind_15(hv3, hv2, hv1, hv0)
Group no_io
Description
- The running evaluation for standard input remains unchanged.
- The running evaluation for standard output remains unchanged.
Polynomials
RunningEvaluationStandardInput' - RunningEvaluationStandardInputRunningEvaluationStandardOutput' - RunningEvaluationStandardOutput
Group no_ram
Description
- The running product for the Permutation Argument with the RAM table does not change.
Polynomials
RunningProductRamTable' - RunningProductRamTable
Group keep_jump_stack
Description
- The jump stack pointer
jspdoes not change. - The jump stack origin
jsodoes not change. - The jump stack destination
jsddoes not change.
Polynomials
jsp' - jspjso' - jsojsd' - jsd
Group step_1
Contains all constraints from instruction group keep_jump_stack, and additionally:
Description
- The instruction pointer increments by 1.
Polynomials
ip' - (ip + 1)
Group step_2
Contains all constraints from instruction group keep_jump_stack, and additionally:
Description
- The instruction pointer increments by 2.
Polynomials
ip' - (ip + 2)
Group grow_op_stack
Description
- The stack element in
st0is moved intost1. - The stack element in
st1is moved intost2. - The stack element in
st2is moved intost3. - The stack element in
st3is moved intost4. - The stack element in
st4is moved intost5. - The stack element in
st5is moved intost6. - The stack element in
st6is moved intost7. - The stack element in
st7is moved intost8. - The stack element in
st8is moved intost9. - The stack element in
st9is moved intost10. - The stack element in
st10is moved intost11. - The stack element in
st11is moved intost12. - The stack element in
st12is moved intost13. - The stack element in
st13is moved intost14. - The stack element in
st14is moved intost15. - The op stack pointer is incremented by 1.
- The running product for the Op Stack Table absorbs the current row with respect to challenges 🍋, 🍊, 🍉, and 🫒 and indeterminate 🪤.
Polynomials
st1' - st0st2' - st1st3' - st2st4' - st3st5' - st4st6' - st5st7' - st6st8' - st7st9' - st8st10' - st9st11' - st10st12' - st11st13' - st12st14' - st13st15' - st14op_stack_pointer' - (op_stack_pointer + 1)RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊·ib1 - 🍉·op_stack_pointer - 🫒·st15)
Group grow_op_stack_by_any_of
Is only ever used in combination with instruction group decompose_arg.
Therefore, the instruction’s argument n correct binary decomposition is known to be in helper variables hv0 through hv3.
Description
- If
nis 1, thenst0is moved intost1
else ifnis 2, thenst0is moved intost2
else ifnis 3, thenst0is moved intost3
else ifnis 4, thenst0is moved intost4
else ifnis 5, thenst0is moved intost5. - If
nis 1, thenst1is moved intost2
else ifnis 2, thenst1is moved intost3
else ifnis 3, thenst1is moved intost4
else ifnis 4, thenst1is moved intost5
else ifnis 5, thenst1is moved intost6. - If
nis 1, thenst2is moved intost3
else ifnis 2, thenst2is moved intost4
else ifnis 3, thenst2is moved intost5
else ifnis 4, thenst2is moved intost6
else ifnis 5, thenst2is moved intost7. - If
nis 1, thenst3is moved intost4
else ifnis 2, thenst3is moved intost5
else ifnis 3, thenst3is moved intost6
else ifnis 4, thenst3is moved intost7
else ifnis 5, thenst3is moved intost8. - If
nis 1, thenst4is moved intost5
else ifnis 2, thenst4is moved intost6
else ifnis 3, thenst4is moved intost7
else ifnis 4, thenst4is moved intost8
else ifnis 5, thenst4is moved intost9. - If
nis 1, thenst5is moved intost6
else ifnis 2, thenst5is moved intost7
else ifnis 3, thenst5is moved intost8
else ifnis 4, thenst5is moved intost9
else ifnis 5, thenst5is moved intost10. - If
nis 1, thenst6is moved intost7
else ifnis 2, thenst6is moved intost8
else ifnis 3, thenst6is moved intost9
else ifnis 4, thenst6is moved intost10
else ifnis 5, thenst6is moved intost11. - If
nis 1, thenst7is moved intost8
else ifnis 2, thenst7is moved intost9
else ifnis 3, thenst7is moved intost10
else ifnis 4, thenst7is moved intost11
else ifnis 5, thenst7is moved intost12. - If
nis 1, thenst8is moved intost9
else ifnis 2, thenst8is moved intost10
else ifnis 3, thenst8is moved intost11
else ifnis 4, thenst8is moved intost12
else ifnis 5, thenst8is moved intost13. - If
nis 1, thenst9is moved intost10
else ifnis 2, thenst9is moved intost11
else ifnis 3, thenst9is moved intost12
else ifnis 4, thenst9is moved intost13
else ifnis 5, thenst9is moved intost14. - If
nis 1, thenst10is moved intost11
else ifnis 2, thenst10is moved intost12
else ifnis 3, thenst10is moved intost13
else ifnis 4, thenst10is moved intost14
else ifnis 5, thenst10is moved intost15. - If
nis 1, thenst11is moved intost12
else ifnis 2, thenst11is moved intost13
else ifnis 3, thenst11is moved intost14
else ifnis 4, thenst11is moved intost15
else ifnis 5, then the op stack pointer grows by 5. - If
nis 1, thenst12is moved intost13
else ifnis 2, thenst12is moved intost14
else ifnis 3, thenst12is moved intost15
else ifnis 4, then the op stack pointer grows by 4
else ifnis 5, then the running product with the Op Stack Table accumulatesst11throughst15. - If
nis 1, thenst13is moved intost14
else ifnis 2, thenst13is moved intost15
else ifnis 3, then the op stack pointer grows by 3
else ifnis 4, then the running product with the Op Stack Table accumulatesst12throughst15. - If
nis 1, thenst14is moved intost15
else ifnis 2, then the op stack pointer grows by 2
else ifnis 3, then the running product with the Op Stack Table accumulatesst13throughst15. - If
nis 1, then the op stack pointer grows by 1
else ifnis 2, then the running product with the Op Stack Table accumulatesst14andst15. - If
nis 1, then the running product with the Op Stack Table accumulatesst15.
Group keep_op_stack_height
The op stack pointer and the running product for the Permutation Argument with the Op Stack Table remain the same. In other words, there is no access (neither read nor write) from/to the Op Stack Table.
Description
- The op stack pointer does not change.
- The running product for the Op Stack Table remains unchanged.
Polynomials
op_stack_pointer' - op_stack_pointerRunningProductOpStackTable' - RunningProductOpStackTable
Group op_stack_remains_except_top_n_elements_unconstrained
Contains all constraints from group keep_op_stack_height, and additionally ensures that all but the top n op stack elements remain the same. (The top n elements are unconstrained.)
Description
- For
iin{n, ..., NUM_OP_STACK_REGISTERS-1}The stack element instidoes not change.
Polynomials
stn' - stn- …
stN' - stN
Group keep_op_stack
Short-hand for op_stack_remains_except_top_n_elements_unconstrained with n=0.
Group binary_operation
Description
- The stack element in
st2is moved intost1. - The stack element in
st3is moved intost2. - The stack element in
st4is moved intost3. - The stack element in
st5is moved intost4. - The stack element in
st6is moved intost5. - The stack element in
st7is moved intost6. - The stack element in
st8is moved intost7. - The stack element in
st9is moved intost8. - The stack element in
st10is moved intost9. - The stack element in
st11is moved intost10. - The stack element in
st12is moved intost11. - The stack element in
st13is moved intost12. - The stack element in
st14is moved intost13. - The stack element in
st15is moved intost14. - The op stack pointer is decremented by 1.
- The running product for the Op Stack Table absorbs clock cycle and instruction bit 1 from the current row as well as op stack pointer and stack element 15 from the next row with respect to challenges 🍋, 🍊, 🍉, and 🫒 and indeterminate 🪤.
Polynomials
st1' - st2st2' - st3st3' - st4st4' - st5st5' - st6st6' - st7st7' - st8st8' - st9st9' - st10st10' - st11st11' - st12st12' - st13st13' - st14st14' - st15op_stack_pointer' - (op_stack_pointer - 1)RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊·ib1 - 🍉·op_stack_pointer' - 🫒·st15')
Group shrink_op_stack
Contains all constraints from instruction group binary_operation, and additionally:
Description
- The stack element in
st1is moved intost0.
Polynomials
st0' - st1
Group shrink_op_stack_by_any_of
Is only ever used in combination with instruction group decompose_arg.
Therefore, the instruction’s argument n correct binary decomposition is known to be in helper variables hv0 through hv3.
Description
- If
nis 1, thenst1is moved intost0
else ifnis 2, thenst2is moved intost0
else ifnis 3, thenst3is moved intost0
else ifnis 4, thenst4is moved intost0
else ifnis 5, thenst5is moved intost0. - If
nis 1, thenst2is moved intost1
else ifnis 2, thenst3is moved intost1
else ifnis 3, thenst4is moved intost1
else ifnis 4, thenst5is moved intost1
else ifnis 5, thenst6is moved intost1. - If
nis 1, thenst3is moved intost2
else ifnis 2, thenst4is moved intost2
else ifnis 3, thenst5is moved intost2
else ifnis 4, thenst6is moved intost2
else ifnis 5, thenst7is moved intost2. - If
nis 1, thenst4is moved intost3
else ifnis 2, thenst5is moved intost3
else ifnis 3, thenst6is moved intost3
else ifnis 4, thenst7is moved intost3
else ifnis 5, thenst8is moved intost3. - If
nis 1, thenst5is moved intost4
else ifnis 2, thenst6is moved intost4
else ifnis 3, thenst7is moved intost4
else ifnis 4, thenst8is moved intost4
else ifnis 5, thenst9is moved intost4. - If
nis 1, thenst6is moved intost5
else ifnis 2, thenst7is moved intost5
else ifnis 3, thenst8is moved intost5
else ifnis 4, thenst9is moved intost5
else ifnis 5, thenst10is moved intost5. - If
nis 1, thenst7is moved intost6
else ifnis 2, thenst8is moved intost6
else ifnis 3, thenst9is moved intost6
else ifnis 4, thenst10is moved intost6
else ifnis 5, thenst11is moved intost6. - If
nis 1, thenst8is moved intost7
else ifnis 2, thenst9is moved intost7
else ifnis 3, thenst10is moved intost7
else ifnis 4, thenst11is moved intost7
else ifnis 5, thenst12is moved intost7. - If
nis 1, thenst9is moved intost8
else ifnis 2, thenst10is moved intost8
else ifnis 3, thenst11is moved intost8
else ifnis 4, thenst12is moved intost8
else ifnis 5, thenst13is moved intost8. - If
nis 1, thenst10is moved intost9
else ifnis 2, thenst11is moved intost9
else ifnis 3, thenst12is moved intost9
else ifnis 4, thenst13is moved intost9
else ifnis 5, thenst14is moved intost9. - If
nis 1, thenst11is moved intost10
else ifnis 2, thenst12is moved intost10
else ifnis 3, thenst13is moved intost10
else ifnis 4, thenst14is moved intost10
else ifnis 5, thenst15is moved intost10. - If
nis 1, thenst12is moved intost11
else ifnis 2, thenst13is moved intost11
else ifnis 3, thenst14is moved intost11
else ifnis 4, thenst15is moved intost11
else ifnis 5, then the op stack pointer shrinks by 5. - If
nis 1, thenst13is moved intost12
else ifnis 2, thenst14is moved intost12
else ifnis 3, thenst15is moved intost12
else ifnis 4, then the op stack pointer shrinks by 4
else ifnis 5, then the running product with the Op Stack Table accumulates next row’sst11throughst15. - If
nis 1, thenst14is moved intost13
else ifnis 2, thenst15is moved intost13
else ifnis 3, then the op stack pointer shrinks by 3
else ifnis 4, then the running product with the Op Stack Table accumulates next row’sst12throughst15. - If
nis 1, thenst15is moved intost14
else ifnis 2, then the op stack pointer shrinks by 2
else ifnis 3, then the running product with the Op Stack Table accumulates next row’sst13throughst15. - If
nis 1, then the op stack pointer shrinks by 1
else ifnis 2, then the running product with the Op Stack Table accumulates next row’sst14andst15. - If
nis 1, then the running product with the Op Stack Table accumulates next row’sst15.
Instruction-Specific Transition Constraints
Instruction push + a
In addition to its instruction groups, this instruction has the following constraints.
Description
- The instruction’s argument
ais moved onto the stack.
Polynomials
st0' - nia
Instruction pop + n
This instruction is fully constrained by its instruction groups
Instruction divine + n
This instruction is fully constrained by its instruction groups
Instruction pick + i
This instruction makes use of indicator polynomials. In addition to its instruction groups, this instruction has the following constraints.
Description
For 0 ⩽ i < 16:
- Stack element
iis moved to the top. - For 0 ⩽
j<i: stack elementjis shifted down by 1. - For
j>i: stack elementjremains unchanged.
Instruction place + i
This instruction makes use of indicator polynomials. In addition to its instruction groups, this instruction has the following constraints.
Description
For 0 ⩽ i < 16:
- Stack element 0 is moved to position
i. - For 0 ⩽
j<i: stack elementjis shifted up by 1. - For
j>i: stack elementjremains unchanged.
Instruction dup + i
This instruction makes use of indicator polynomials. In addition to its instruction groups, this instruction has the following constraints.
Description
- If
iis 0, thenst0is put on top of the stack and
ifiis 1, thenst1is put on top of the stack and
ifiis 2, thenst2is put on top of the stack and
ifiis 3, thenst3is put on top of the stack and
ifiis 4, thenst4is put on top of the stack and
ifiis 5, thenst5is put on top of the stack and
ifiis 6, thenst6is put on top of the stack and
ifiis 7, thenst7is put on top of the stack and
ifiis 8, thenst8is put on top of the stack and
ifiis 9, thenst9is put on top of the stack and
ifiis 10, thenst10is put on top of the stack and
ifiis 11, thenst11is put on top of the stack and
ifiis 12, thenst12is put on top of the stack and
ifiis 13, thenst13is put on top of the stack and
ifiis 14, thenst14is put on top of the stack and
ifiis 15, thenst15is put on top of the stack.
Polynomials
ind_0(hv3, hv2, hv1, hv0)·(st0' - st0)
+ ind_1(hv3, hv2, hv1, hv0)·(st0' - st1)
+ ind_2(hv3, hv2, hv1, hv0)·(st0' - st2)
+ ind_3(hv3, hv2, hv1, hv0)·(st0' - st3)
+ ind_4(hv3, hv2, hv1, hv0)·(st0' - st4)
+ ind_5(hv3, hv2, hv1, hv0)·(st0' - st5)
+ ind_6(hv3, hv2, hv1, hv0)·(st0' - st6)
+ ind_7(hv3, hv2, hv1, hv0)·(st0' - st7)
+ ind_8(hv3, hv2, hv1, hv0)·(st0' - st8)
+ ind_9(hv3, hv2, hv1, hv0)·(st0' - st9)
+ ind_10(hv3, hv2, hv1, hv0)·(st0' - st10)
+ ind_11(hv3, hv2, hv1, hv0)·(st0' - st11)
+ ind_12(hv3, hv2, hv1, hv0)·(st0' - st12)
+ ind_13(hv3, hv2, hv1, hv0)·(st0' - st13)
+ ind_14(hv3, hv2, hv1, hv0)·(st0' - st14)
+ ind_15(hv3, hv2, hv1, hv0)·(st0' - st15)
Instruction swap + i
This instruction makes use of indicator polynomials. In addition to its instruction groups, this instruction has the following constraints.
Description
For 0 ⩽ i < 16:
- Stack element
iis moved to the top. - The top stack element is moved to position
i - For
j≠i: stack elementjremains unchanged.
Instruction nop
This instruction is fully constrained by its instruction groups
Instruction skiz
For the correct behavior of instruction skiz, the instruction pointer ip needs to increment by either 1, or 2, or 3.
The concrete value depends on the top of the stack st0 and the next instruction, held in nia.
Helper variable hv0 helps with identifying whether st0 is 0.
To this end, it holds the inverse-or-zero of st0, i.e., is 0 if and only if st0 is 0, and is the inverse of st0 otherwise.
Efficient arithmetization of instruction skiz makes use of one of the properties of
opcodes.
Concretely, the least significant bit of an opcode is 1 if and only if the instruction takes an argument.
The arithmetization of skiz can incorporate this simple flag by decomposing nia into helper variable registers hv,
similarly to how ci is (always) deconstructed into instruction bit registers ib.
Correct decomposition is guaranteed by employing a range check.
In addition to its instruction groups, this instruction has the following constraints.
Description
- Helper variable
hv1is the inverse ofst0or 0. - Helper variable
hv1is the inverse ofst0orst0is 0. - The next instruction
niais decomposed into helper variableshv1throughhv5. - The indicator helper variable
hv1is either 0 or 1. Here,hv1 == 1means thatniatakes an argument. - The helper variable
hv2is either 0 or 1 or 2 or 3. - The helper variable
hv3is either 0 or 1 or 2 or 3. - The helper variable
hv4is either 0 or 1 or 2 or 3. - The helper variable
hv5is either 0 or 1 or 2 or 3. - If
st0is non-zero, registeripis incremented by 1. Ifst0is 0 andniatakes no argument, registeripis incremented by 2. Ifst0is 0 andniatakes an argument, registeripis incremented by 3.
Written as Disjunctive Normal Form, the last constraint can be expressed as:
- (Register
st0is 0 oripis incremented by 1), and (st0has a multiplicative inverse orhv1is 1 oripis incremented by 2), and (st0has a multiplicative inverse orhv1is 0 oripis incremented by 3).
Since the three cases are mutually exclusive, the three respective polynomials can be summed up into one.
Polynomials
(st0·hv0 - 1)·hv0(st0·hv0 - 1)·st0nia - hv1 - 2·hv2 - 8·hv3 - 32·hv4 - 128·hv5hv1·(hv1 - 1)hv2·(hv2 - 1)·(hv2 - 2)·(hv2 - 3)hv3·(hv3 - 1)·(hv3 - 2)·(hv3 - 3)hv4·(hv4 - 1)·(hv4 - 2)·(hv4 - 3)hv5·(hv5 - 1)·(hv5 - 2)·(hv5 - 3)(ip' - (ip + 1)·st0)
+ ((ip' - (ip + 2))·(st0·hv0 - 1)·(hv1 - 1))
+ ((ip' - (ip + 3))·(st0·hv0 - 1)·hv1)
Helper variable definitions for skiz
hv0 = inverse(st0)(ifst0 ≠ 0)hv1 = nia mod 2hv2 = (nia >> 1) mod 4hv3 = (nia >> 3) mod 4hv4 = (nia >> 5) mod 4hv5 = nia >> 7
Instruction call + d
In addition to its instruction groups, this instruction has the following constraints.
Description
- The jump stack pointer
jspis incremented by 1. - The jump’s origin
jsois set to the current instruction pointeripplus 2. - The jump’s destination
jsdis set to the instruction’s argumentd. - The instruction pointer
ipis set to the instruction’s argumentd.
Polynomials
jsp' - (jsp + 1)jso' - (ip + 2)jsd' - niaip' - nia
Instruction return
In addition to its instruction groups, this instruction has the following constraints.
Description
- The jump stack pointer
jspis decremented by 1. - The instruction pointer
ipis set to the last call’s originjso.
Polynomials
jsp' - (jsp - 1)ip' - jso
Instruction recurse
In addition to its instruction groups, this instruction has the following constraints.
Description
- The jump stack pointer
jspdoes not change. - The last jump’s origin
jsodoes not change. - The last jump’s destination
jsddoes not change. - The instruction pointer
ipis set to the last jump’s destinationjsd.
Polynomials
jsp' - jspjso' - jsojsd' - jsdip' - jsd
Instruction recurse_or_return
In addition to its instruction groups, this instruction has the following constraints.
Description
- If
ST5equalsST6, thenipin the next row equalsjsoin the current row. - If
ST5equalsST6, thenjspdecrements by one. - If
ST5equalsST6, thenhv0in the current row is 0. - If
ST5is unequal toST6, thenhv0in the current row is the inverse of(ST6 - ST5). - If
ST5is unequal toST6, thenipin the next row is equal tojsdin the current row. - If
ST5is unequal toST6, thenjspremains unchanged. - If
ST5is unequal toST6, thenjsoremains unchanged. - If
ST5is unequal toST6, thenjsdremains unchanged.
Helper variable definitions for recurse_or_return
To help arithmetizing the equality check between ST5 and ST6, helper variable hv0 is the inverse-or-zero of (ST6 - ST5).
Instruction assert
In addition to its instruction groups, this instruction has the following constraints.
Description
- The current top of the stack
st0is 1.
Polynomials
st0 - 1
Instruction halt
In addition to its instruction groups, this instruction has the following constraints.
Description
- The instruction executed in the following step is instruction
halt.
Polynomials
ci' - ci
Instruction read_mem + n
In addition to its instruction groups, this instruction has the following constraints.
Description
- The RAM pointer
st0is decremented byn. - If
nis 1, thenst1is moved intost2
else ifnis 2, thenst1is moved intost3
else ifnis 3, thenst1is moved intost4
else ifnis 4, thenst1is moved intost5
else ifnis 5, thenst1is moved intost6. - If
nis 1, thenst2is moved intost3
else ifnis 2, thenst2is moved intost4
else ifnis 3, thenst2is moved intost5
else ifnis 4, thenst2is moved intost6
else ifnis 5, thenst2is moved intost7. - If
nis 1, thenst3is moved intost4
else ifnis 2, thenst3is moved intost5
else ifnis 3, thenst3is moved intost6
else ifnis 4, thenst3is moved intost7
else ifnis 5, thenst3is moved intost8. - If
nis 1, thenst4is moved intost5
else ifnis 2, thenst4is moved intost6
else ifnis 3, thenst4is moved intost7
else ifnis 4, thenst4is moved intost8
else ifnis 5, thenst4is moved intost9. - If
nis 1, thenst5is moved intost6
else ifnis 2, thenst5is moved intost7
else ifnis 3, thenst5is moved intost8
else ifnis 4, thenst5is moved intost9
else ifnis 5, thenst5is moved intost10. - If
nis 1, thenst6is moved intost7
else ifnis 2, thenst6is moved intost8
else ifnis 3, thenst6is moved intost9
else ifnis 4, thenst6is moved intost10
else ifnis 5, thenst6is moved intost11. - If
nis 1, thenst7is moved intost8
else ifnis 2, thenst7is moved intost9
else ifnis 3, thenst7is moved intost10
else ifnis 4, thenst7is moved intost11
else ifnis 5, thenst7is moved intost12. - If
nis 1, thenst8is moved intost9
else ifnis 2, thenst8is moved intost10
else ifnis 3, thenst8is moved intost11
else ifnis 4, thenst8is moved intost12
else ifnis 5, thenst8is moved intost13. - If
nis 1, thenst9is moved intost10
else ifnis 2, thenst9is moved intost11
else ifnis 3, thenst9is moved intost12
else ifnis 4, thenst9is moved intost13
else ifnis 5, thenst9is moved intost14. - If
nis 1, thenst10is moved intost11
else ifnis 2, thenst10is moved intost12
else ifnis 3, thenst10is moved intost13
else ifnis 4, thenst10is moved intost14
else ifnis 5, thenst10is moved intost15. - If
nis 1, thenst11is moved intost12
else ifnis 2, thenst11is moved intost13
else ifnis 3, thenst11is moved intost14
else ifnis 4, thenst11is moved intost15
else ifnis 5, then the op stack pointer grows by 5. - If
nis 1, thenst12is moved intost13
else ifnis 2, thenst12is moved intost14
else ifnis 3, thenst12is moved intost15
else ifnis 4, then the op stack pointer grows by 4
else ifnis 5, then with the Op Stack Table accumulatesst11throughst15. - If
nis 1, thenst13is moved intost14
else ifnis 2, thenst13is moved intost15
else ifnis 3, then the op stack pointer grows by 3
else ifnis 4, then the running product with the Op Stack Table accumulatesst12throughst15
else ifnis 5, then the running product with the RAM Table accumulates next row’sst1throughst5. - If
nis 1, thenst14is moved intost15
else ifnis 2, then the op stack pointer grows by 2
else ifnis 3, then the running product with the Op Stack Table accumulatesst13throughst15
else ifnis 4, then the running product with the RAM Table accumulates next row’sst1throughst4 - If
nis 1, then the op stack pointer grows by 1
else ifnis 2, then the running product with the Op Stack Table accumulatesst14andst15
else ifnis 3, then the running product with the RAM Table accumulates next row’sst1throughst3. - If
nis 1, then the running product with the Op Stack Table accumulatesst15
else ifnis 2, then the running product with the RAM Table accumulates next row’sst1andst2. - If
nis 1, then the running product with the RAM Table accumulates next row’sst1.
Instruction write_mem + n
In addition to its instruction groups, this instruction has the following constraints.
Description
- The RAM pointer
st0is incremented byn. - If
nis 1, thenst2is moved intost1
else ifnis 2, thenst3is moved intost1
else ifnis 3, thenst4is moved intost1
else ifnis 4, thenst5is moved intost1
else ifnis 5, thenst6is moved intost1. - If
nis 1, thenst3is moved intost2
else ifnis 2, thenst4is moved intost2
else ifnis 3, thenst5is moved intost2
else ifnis 4, thenst6is moved intost2
else ifnis 5, thenst7is moved intost2. - If
nis 1, thenst4is moved intost3
else ifnis 2, thenst5is moved intost3
else ifnis 3, thenst6is moved intost3
else ifnis 4, thenst7is moved intost3
else ifnis 5, thenst8is moved intost3. - If
nis 1, thenst5is moved intost4
else ifnis 2, thenst6is moved intost4
else ifnis 3, thenst7is moved intost4
else ifnis 4, thenst8is moved intost4
else ifnis 5, thenst9is moved intost4. - If
nis 1, thenst6is moved intost5
else ifnis 2, thenst7is moved intost5
else ifnis 3, thenst8is moved intost5
else ifnis 4, thenst9is moved intost5
else ifnis 5, thenst10is moved intost5. - If
nis 1, thenst7is moved intost6
else ifnis 2, thenst8is moved intost6
else ifnis 3, thenst9is moved intost6
else ifnis 4, thenst10is moved intost6
else ifnis 5, thenst11is moved intost6. - If
nis 1, thenst8is moved intost7
else ifnis 2, thenst9is moved intost7
else ifnis 3, thenst10is moved intost7
else ifnis 4, thenst11is moved intost7
else ifnis 5, thenst12is moved intost7. - If
nis 1, thenst9is moved intost8
else ifnis 2, thenst10is moved intost8
else ifnis 3, thenst11is moved intost8
else ifnis 4, thenst12is moved intost8
else ifnis 5, thenst13is moved intost8. - If
nis 1, thenst10is moved intost9
else ifnis 2, thenst11is moved intost9
else ifnis 3, thenst12is moved intost9
else ifnis 4, thenst13is moved intost9
else ifnis 5, thenst14is moved intost9. - If
nis 1, thenst11is moved intost10
else ifnis 2, thenst12is moved intost10
else ifnis 3, thenst13is moved intost10
else ifnis 4, thenst14is moved intost10
else ifnis 5, thenst15is moved intost10. - If
nis 1, thenst12is moved intost11
else ifnis 2, thenst13is moved intost11
else ifnis 3, thenst14is moved intost11
else ifnis 4, thenst15is moved intost11
else ifnis 5, then the op stack pointer shrinks by 5. - If
nis 1, thenst13is moved intost12
else ifnis 2, thenst14is moved intost12
else ifnis 3, thenst15is moved intost12
else ifnis 4, then the op stack pointer shrinks by 4
else ifnis 5, then the running product with the Op Stack Table accumulates next row’sst11throughst15. - If
nis 1, thenst14is moved intost13
else ifnis 2, thenst15is moved intost13
else ifnis 3, then the op stack pointer shrinks by 3
else ifnis 4, then the running product with the Op Stack Table accumulates next row’sst12throughst15
else ifnis 5, then the running product with the RAM Table accumulatesst1throughst5. - If
nis 1, thenst15is moved intost14
else ifnis 2, then the op stack pointer shrinks by 2
else ifnis 3, then the running product with the Op Stack Table accumulates next row’sst13throughst15
else ifnis 4, then the running product with the RAM Table accumulatesst1throughst4. - If
nis 1, then the op stack pointer shrinks by 1
else ifnis 2, then the running product with the Op Stack Table accumulates next row’sst14andst15
else ifnis 3, then the running product with the RAM Table accumulatesst1throughst2. - If
nis 1, then the running product with the Op Stack Table accumulates next row’sst15
else ifnis 2, then the running product with the RAM Table accumulatesst1andst1. - If
nis 1, then the running product with the RAM Table accumulatesst1.
Instruction hash
In addition to its instruction groups, this instruction has the following constraints.
Description
st10is moved intost5.st11is moved intost6.st12is moved intost7.st13is moved intost8.st14is moved intost9.st15is moved intost10.- The op stack pointer shrinks by 5.
- The running product with the Op Stack Table accumulates next row’s
st11throughst15.
Polynomials
st5' - st10st6' - st11st7' - st12st8' - st13st9' - st14st10' - st15op_stack_pointer' - op_stack_pointer + 5RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊 - 🍉·op_stack_pointer' - 🫒·st15')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 1) - 🫒·st14')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 2) - 🫒·st13')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 3) - 🫒·st12')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 4) - 🫒·st11')
Instruction assert_vector
In addition to its instruction groups, this instruction has the following constraints.
Description
st0is equal tost5.st1is equal tost6.st2is equal tost7.st3is equal tost8.st4is equal tost9.st10is moved intost5.st11is moved intost6.st12is moved intost7.st13is moved intost8.st14is moved intost9.st15is moved intost10.- The op stack pointer shrinks by 5.
- The running product with the Op Stack Table accumulates next row’s
st11throughst15.
Polynomials
st5 - st0st6 - st1st7 - st2st8 - st3st9 - st4st5' - st10st6' - st11st7' - st12st8' - st13st9' - st14st10' - st15op_stack_pointer' - op_stack_pointer + 5RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊 - 🍉·op_stack_pointer' - 🫒·st15')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 1) - 🫒·st14')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 2) - 🫒·st13')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 3) - 🫒·st12')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 4) - 🫒·st11')
Instruction sponge_init
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the Hash Table.
Instruction sponge_absorb
In addition to its instruction groups, this instruction has the following constraints. Beyond that, correct transition is guaranteed by the Hash Table.
Description
st10is moved intost0.st11is moved intost1.st12is moved intost2.st13is moved intost3.st14is moved intost4.st15is moved intost5.- The op stack pointer shrinks by 10.
- The running product with the Op Stack Table accumulates next row’s
st6throughst15.
Polynomials
st0' - st10st1' - st11st2' - st12st3' - st13st4' - st14st5' - st15op_stack_pointer' - op_stack_pointer + 10RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊 - 🍉·op_stack_pointer' - 🫒·st15')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 1) - 🫒·st14')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 2) - 🫒·st13')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 3) - 🫒·st12')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 4) - 🫒·st11')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 5) - 🫒·st10')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 6) - 🫒·st9')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 7) - 🫒·st8')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 8) - 🫒·st7')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 9) - 🫒·st6')
Instruction sponge_absorb_mem
In addition to its instruction groups, this instruction has the following constraints. Beyond that, correct transition is guaranteed by the Hash Table and the RAM Table.
Description
st0is incremented by 10.
Instruction sponge_squeeze
In addition to its instruction groups, this instruction has the following constraints. Beyond that, correct transition is guaranteed by the Hash Table.
Description
st0is moved intost10.st1is moved intost11.st2is moved intost12.st3is moved intost13.st4is moved intost14.st5is moved intost15.- The op stack pointer grows by 10.
- The running product with the Op Stack Table accumulates
st6throughst15.
Polynomials
st10' - st0st11' - st1st12' - st2st13' - st3st14' - st4st15' - st5op_stack_pointer' - op_stack_pointer - 10RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍉·op_stack_pointer - 🫒·st15)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 1) - 🫒·st14)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 2) - 🫒·st13)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 3) - 🫒·st12)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 4) - 🫒·st11)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 5) - 🫒·st10)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 6) - 🫒·st9)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 7) - 🫒·st8)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 8) - 🫒·st7)
·(🪤 - 🍋·clk - 🍉·(op_stack_pointer + 9) - 🫒·st6)
Instruction add
In addition to its instruction groups, this instruction has the following constraints.
Description
- The sum of the top two stack elements is moved into the top of the stack.
Polynomials
st0' - (st0 + st1)
Instruction mul
In addition to its instruction groups, this instruction has the following constraints.
Description
- The product of the top two stack elements is moved into the top of the stack.
Polynomials
st0' - st0·st1
Instruction invert
In addition to its instruction groups, this instruction has the following constraints.
Description
- The top of the stack’s inverse is moved into the top of the stack.
Polynomials
st0'·st0 - 1
Instruction eq
In addition to its instruction groups, this instruction has the following constraints.
Description
- Helper variable
hv0is the inverse of the difference of the stack’s two top-most elements or 0. - Helper variable
hv0is the inverse of the difference of the stack’s two top-most elements or the difference is 0. - The new top of the stack is 1 if the difference between the stack’s two top-most elements is not invertible, 0 otherwise.
Polynomials
hv0·(hv0·(st1 - st0) - 1)(st1 - st0)·(hv0·(st1 - st0) - 1)st0' - (1 - hv0·(st1 - st0))
Helper variable definitions for eq
hv0 = inverse(rhs - lhs)ifrhs ≠ lhs.hv0 = 0ifrhs = lhs.
Instruction split
In addition to its instruction groups, this instruction has the following constraints. Part of the correct transition, namely the range check on the instruction’s result, is guaranteed by the U32 Table.
Description
- The top of the stack is decomposed as 32-bit chunks into the stack’s top-most two elements.
- Helper variable
hv0holds the inverse of subtracted from the high 32 bits or the low 32 bits are 0.
Polynomials
st0 - (2^32·st1' + st0')st0'·(hv0·(st1' - (2^32 - 1)) - 1)
Helper variable definitions for split
Given the high 32 bits of st0 as hi = st0 >> 32 and the low 32 bits of st0 as lo = st0 & 0xffff_ffff,
hv0 = (hi - (2^32 - 1))iflo ≠ 0.hv0 = 0iflo = 0.
Instruction lt
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the U32 Table.
Instruction and
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the U32 Table.
Instruction xor
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the U32 Table.
Instruction log2floor
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the U32 Table.
Instruction pow
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the U32 Table.
Instruction div_mod
Recall that instruction div_mod takes stack _ d n and computes _ q r where n is the numerator, d is the denominator, r is the remainder, and q is the quotient.
The following two properties are guaranteed by the U32 Table:
- The remainder
ris smaller than the denominatord, and - all four of
n,d,q, andrare u32s.
In addition to its instruction groups, this instruction has the following constraints.
Description
- Numerator is quotient times denominator plus remainder:
n == q·d + r.
Polynomials
st0 - st1·st1' - st0'st2' - st2
Instruction pop_count
This instruction is fully constrained by its instruction groups Beyond that, correct transition is guaranteed by the U32 Table.
Instruction xx_add
In addition to its instruction groups, this instruction has the following constraints.
Description
- The result of adding
st0tost3is moved intost0. - The result of adding
st1tost4is moved intost1. - The result of adding
st2tost5is moved intost2. st6is moved intost3.st7is moved intost4.st8is moved intost5.st9is moved intost6.st10is moved intost7.st11is moved intost8.st12is moved intost9.st13is moved intost10.st14is moved intost11.st15is moved intost12.- The op stack pointer shrinks by 3.
- The running product with the Op Stack Table accumulates next row’s
st13throughst15.
Polynomials
st0' - (st0 + st3)st1' - (st1 + st4)st2' - (st2 + st5)st3' - st6st4' - st7st5' - st8st6' - st9st7' - st10st8' - st11st9' - st12st10' - st13st11' - st14st12' - st15op_stack_pointer' - op_stack_pointer + 3RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊 - 🍉·op_stack_pointer' - 🫒·st15')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 1) - 🫒·st14')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 2) - 🫒·st13')
Instruction xx_mul
In addition to its instruction groups, this instruction has the following constraints.
Description
- The coefficient of x^0 of multiplying the two X-Field elements on the stack is moved into
st0. - The coefficient of x^1 of multiplying the two X-Field elements on the stack is moved into
st1. - The coefficient of x^2 of multiplying the two X-Field elements on the stack is moved into
st2. st6is moved intost3.st7is moved intost4.st8is moved intost5.st9is moved intost6.st10is moved intost7.st11is moved intost8.st12is moved intost9.st13is moved intost10.st14is moved intost11.st15is moved intost12.- The op stack pointer shrinks by 3.
- The running product with the Op Stack Table accumulates next row’s
st13throughst15.
Polynomials
st0' - (st0·st3 - st2·st4 - st1·st5)st1' - (st1·st3 + st0·st4 - st2·st5 + st2·st4 + st1·st5)st2' - (st2·st3 + st1·st4 + st0·st5 + st2·st5)st3' - st6st4' - st7st5' - st8st6' - st9st7' - st10st8' - st11st9' - st12st10' - st13st11' - st14st12' - st15op_stack_pointer' - op_stack_pointer + 3RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊 - 🍉·op_stack_pointer' - 🫒·st15')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 1) - 🫒·st14')
·(🪤 - 🍋·clk - 🍊 - 🍉·(op_stack_pointer' + 2) - 🫒·st13')
Instruction x_invert
In addition to its instruction groups, this instruction has the following constraints.
Description
- The coefficient of x^0 of multiplying X-Field element on top of the current stack and on top of the next stack is 1.
- The coefficient of x^1 of multiplying X-Field element on top of the current stack and on top of the next stack is 0.
- The coefficient of x^2 of multiplying X-Field element on top of the current stack and on top of the next stack is 0.
Polynomials
st0·st0' - st2·st1' - st1·st2' - 1st1·st0' + st0·st1' - st2·st2' + st2·st1' + st1·st2'st2·st0' + st1·st1' + st0·st2' + st2·st2'
Instruction xb_mul
In addition to its instruction groups, this instruction has the following constraints.
Description
- The result of multiplying the top of the stack with the X-Field element’s coefficient for x^0 is moved into
st0. - The result of multiplying the top of the stack with the X-Field element’s coefficient for x^1 is moved into
st1. - The result of multiplying the top of the stack with the X-Field element’s coefficient for x^2 is moved into
st2. st4is moved intost3.st5is moved intost4.st6is moved intost5.st7is moved intost6.st8is moved intost7.st9is moved intost8.st10is moved intost9.st11is moved intost10.st12is moved intost11.st13is moved intost12.st14is moved intost13.st15is moved intost14.- The op stack pointer shrinks by 3.
- The running product with the Op Stack Table accumulates next row’s
st15.
Polynomials
st0' - st0·st1st1' - st0·st2st2' - st0·st3st3' - st4st4' - st5st5' - sttst6' - st7st7' - st8st8' - st9st9' - st10st10' - st11st11' - st12st12' - st13st13' - st14st14' - st15op_stack_pointer' - op_stack_pointer + 1RunningProductOpStackTable' - RunningProductOpStackTable·(🪤 - 🍋·clk - 🍊 - 🍉·op_stack_pointer' - 🫒·st15')
Instruction read_io + n
In addition to its instruction groups, this instruction has the following constraints.
Description
- If
nis 1, the running evaluation for standard input accumulates next row’sst0
else ifnis 2, the running evaluation for standard input accumulates next row’sst0andst1
else ifnis 3, the running evaluation for standard input accumulates next row’sst0throughst2
else ifnis 4, the running evaluation for standard input accumulates next row’sst0throughst3
else ifnis 5, the running evaluation for standard input accumulates next row’sst0throughst4.
Polynomials
ind_1(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardInput' - 🛏·RunningEvaluationStandardInput - st0')
+ ind_2(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardInput' - 🛏·(🛏·RunningEvaluationStandardInput - st0') - st1')
+ ind_3(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardInput' - 🛏·(🛏·(🛏·RunningEvaluationStandardInput - st0') - st1') - st2')
+ ind_4(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardInput' - 🛏·(🛏·(🛏·(🛏·RunningEvaluationStandardInput - st0') - st1') - st2') - st3')
+ ind_5(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardInput' - 🛏·(🛏·(🛏·(🛏·(🛏·RunningEvaluationStandardInput - st0') - st1') - st2') - st3') - st4')
Instruction write_io + n
In addition to its instruction groups, this instruction has the following constraints.
Description
- If
nis 1, the running evaluation for standard output accumulatesst0
else ifnis 2, the running evaluation for standard output accumulatesst0andst1
else ifnis 3, the running evaluation for standard output accumulatesst0throughst2
else ifnis 4, the running evaluation for standard output accumulatesst0throughst3
else ifnis 5, the running evaluation for standard output accumulatesst0throughst4.
Polynomials
ind_1(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardOutput' - 🧯·RunningEvaluationStandardOutput - st0)
+ ind_2(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardOutput' - 🧯·(🧯·RunningEvaluationStandardOutput - st0) - st1)
+ ind_3(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardOutput' - 🧯·(🧯·(🧯·RunningEvaluationStandardOutput - st0) - st1) - st2)
+ ind_4(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardOutput' - 🧯·(🧯·(🧯·(🧯·RunningEvaluationStandardOutput - st0) - st1) - st2) - st3)
+ ind_5(hv3, hv2, hv1, hv0)·(RunningEvaluationStandardOutput' - 🧯·(🧯·(🧯·(🧯·(🧯·RunningEvaluationStandardOutput - st0) - st1) - st2) - st3) - st4)
Instruction merkle_step
Recall that in a Merkle tree, the indices of left (respectively right) leaves have 0 (respectively 1) as their least significant bit. This motivates the use of a helper variable to hold that least significant bit.
In addition to its instruction groups, this instruction has the following constraints. The two Evaluation Arguments also used for instruction hash guarantee correct transition of the top of the stack.
Description
- Helper variable
hv5is either 0 or 1. st5is shifted by 1 bit to the right. In other words, twicest5in the next row plushv5equalsst5in the current row.
Helper variable definitions for merkle_step
hv0throughhv4hold the sibling digest of the node indicated byst5, as read from the interface for non-deterministic input.hv5holds the result ofst5 % 2, the Merkle tree node index’s least significant bit, indicating whether it is a left or right node.
Instruction merkle_step_mem
In addition to its instruction groups, this instruction has the following constraints.
The two Evaluation Arguments also used for instruction hash guarantee correct transition of the top of the stack.
See also merkle_step.
Description
- Stack element
st6does not change. - Stack element
st7is incremented by 5. - Helper variable
hv5is either 0 or 1. st5is shifted by 1 bit to the right. In other words, twicest5in the next row plushv5equalsst5in the current row.- The running product with the RAM Table accumulates
hv0throughhv4using the (appropriately adjusted) RAM pointer held inst7.
Helper variable definitions for merkle_step_mem
hv0throughhv4hold the sibling digest of the node indicated byst5, as read from RAM at the address held inst7.hv5holds the result ofst5 % 2, the Merkle tree node index’s least significant bit, indicating whether it is a left or right node.
Instruction xx_dot_step
In addition to its instruction groups, this instruction has the following constraints.
Description
- Store
(RAM[st0], RAM[st0+1], RAM[st0+2])in(hv0, hv1, hv2). - Store
(RAM[st1], RAM[st1+1], RAM[st1+2])in(hv3, hv4, hv5). - Add
(hv0 + hv1·x + hv2·x²) · (hv3 + hv4·x + hv5·x²)into(st2, st3, st4) - Increase the pointers:
st0andst1by 3 each.
Instruction xb_dot_step
In addition to its instruction groups, this instruction has the following constraints.
Description
- Store
RAM[st0]inhv0. - Store
(RAM[st1], RAM[st1+1], RAM[st1+2])in(hv1, hv2, hv3). - Add
hv0 · (hv1 + hv2·x + hv3·x²)into(st1, st2, st3) - Increase the pointers:
st0andst1by 1 and 3, respectively.
Operational Stack Table
The operational stack1 is where the program stores simple elementary operations, function arguments, and pointers to important objects.
There are 16 registers (st0 through st15) that the program can access directly.
These registers correspond to the top of the stack.
They are recorded in the Processor Table.
The rest of the op stack is stored in a dedicated memory object called “operational stack underflow memory”. It is initially empty. The evolution of the underflow memory is recorded in the Op Stack Table. The sole task of the Op Stack Table is to keep underflow memory immutable. To achieve this, any read or write accesses to the underflow memory are recorded in the Op Stack Table. Read and write accesses to op stack underflow memory are a side effect of shrinking or growing the op stack.
Main Columns
The Op Stack Table consists of 4 columns:
- the cycle counter
clk - the shrink stack indicator
shrink_stack, corresponding to the processor’s instruction bit 1ib1, - the op stack pointer
stack_pointer, and - the first underflow element
first_underflow_element.
| Clock | Shrink Stack Indicator | Stack Pointer | First Underflow Element |
|---|---|---|---|
| - | - | - | - |
Column clk records the processor’s execution cycle during which the read or write access happens.
The shrink_stack indicator signals whether the underflow memory access is a read or a write:
a read corresponds to a shrinking stack is indicated by a 1, a write corresponds to a growing stack and is indicated by a 0.
The same column doubles up as a padding indicator, in which case shrink_stack is set to 2.
The stack_pointer is the address at which the to-be-read-or-written element resides.
Finally, the first_underflow_element is the stack element being transferred from stack register st15 into underflow memory on a write, or the other way around on a read.
A subset Permutation Argument with the Processor Table establishes that the rows recorded in the Op Stack Table are consistent with the processor’s part of the op stack.
In order to guarantee memory consistency, the rows of the operational stack table are sorted by stack_pointer first, cycle count clk second.
The mechanics are best illustrated by an example.
Observe how the malicious manipulation of the Op Stack Underflow Memory, the change of “42” into “99” in cycle 8, is detected:
The transition constraints of the Op Stack Table stipulate that if stack_pointer does not change, then the first_underflow_element can only change if the next instruction grows the stack.
Consequently, row [4, 0, 8, 42] being followed by row [10, 1, 8, 99] violates the constraints.
The shrink stack indicator being correct is guaranteed by the Permutation Argument between Op Stack Table and the Processor Table.
For illustrative purposes only, we use four stack registers st0 through st3 in the example.
Triton VM has 16 stack registers, st0 through st15.
Furthermore, implied next instructions usually recorded in register “next instruction or argument” nia are omitted for reasons of readability.
Processor’s execution trace:
clk | ci | nia | st0 | st1 | st2 | st3 | Op Stack Underflow Memory | op_stack_pointer |
|---|---|---|---|---|---|---|---|---|
| 0 | push | 42 | 0 | 0 | 0 | 0 | [] | 4 |
| 1 | push | 43 | 42 | 0 | 0 | 0 | [ 0] | 5 |
| 2 | push | 44 | 43 | 42 | 0 | 0 | [ 0, 0] | 6 |
| 3 | push | 45 | 44 | 43 | 42 | 0 | [ 0, 0, 0] | 7 |
| 4 | push | 46 | 45 | 44 | 43 | 42 | [ 0, 0, 0, 0] | 8 |
| 5 | push | 47 | 46 | 45 | 44 | 43 | [42, 0, 0, 0, 0] | 9 |
| 6 | push | 48 | 47 | 46 | 45 | 44 | [43, 42, 0, 0, 0, 0] | 10 |
| 7 | nop | 48 | 47 | 46 | 45 | [44, 43, 42, 0, 0, 0] | 11 | |
| 8 | pop | 48 | 47 | 46 | 45 | [44, 43, 99, 0, 0, 0] | 11 | |
| 9 | pop | 47 | 46 | 45 | 44 | [43, 99, 0, 0, 0, 0] | 10 | |
| 10 | pop | 46 | 45 | 44 | 43 | [99, 0, 0, 0, 0] | 9 | |
| 11 | pop | 45 | 44 | 43 | 99 | [ 0, 0, 0, 0] | 8 | |
| 12 | push | 77 | 44 | 43 | 99 | 0 | [ 0, 0, 0] | 7 |
| 13 | swap | 3 | 77 | 44 | 43 | 99 | [ 0, 0, 0, 0] | 8 |
| 14 | push | 78 | 99 | 44 | 43 | 77 | [ 0, 0, 0, 0] | 8 |
| 15 | swap | 3 | 78 | 99 | 44 | 43 | [77, 0, 0, 0, 0] | 9 |
| 16 | push | 79 | 43 | 99 | 44 | 78 | [77, 0, 0, 0, 0] | 9 |
| 17 | pop | 79 | 43 | 99 | 44 | [78, 77, 0, 0, 0, 0] | 10 | |
| 18 | pop | 43 | 99 | 44 | 78 | [77, 0, 0, 0, 0] | 9 | |
| 19 | pop | 99 | 44 | 78 | 77 | [ 0, 0, 0, 0] | 8 | |
| 20 | pop | 44 | 78 | 77 | 0 | [ 0, 0, 0] | 7 | |
| 21 | pop | 78 | 77 | 0 | 0 | [ 0, 0] | 6 | |
| 22 | pop | 77 | 0 | 0 | 0 | [ 0] | 5 | |
| 23 | halt | 0 | 0 | 0 | 0 | [] | 4 |
Operational Stack Table:
clk | shrink_stack | stack_pointer | first_underflow_element |
|---|---|---|---|
| 0 | 0 | 4 | 0 |
| 22 | 1 | 4 | 0 |
| 1 | 0 | 5 | 0 |
| 21 | 1 | 5 | 0 |
| 2 | 0 | 6 | 0 |
| 20 | 1 | 6 | 0 |
| 3 | 0 | 7 | 0 |
| 11 | 1 | 7 | 0 |
| 12 | 0 | 7 | 0 |
| 19 | 1 | 7 | 0 |
| 4 | 0 | 8 | 42 |
| 10 | 1 | 8 | 99 |
| 14 | 0 | 8 | 77 |
| 18 | 1 | 8 | 77 |
| 5 | 0 | 9 | 43 |
| 9 | 1 | 9 | 43 |
| 16 | 0 | 9 | 78 |
| 17 | 1 | 9 | 78 |
| 6 | 0 | 10 | 44 |
| 8 | 1 | 10 | 44 |
Auxiliary Columns
The Op Stack Table has 2 auxiliary columns, rppa and ClockJumpDifferenceLookupClientLogDerivative.
- A Permutation Argument establishes that the rows of the Op Stack Table correspond to the rows of the Processor Table.
The running product for this argument is contained in the
rppacolumn. - In order to achieve memory consistency, a Lookup Argument shows that all clock jump differences are contained in the
clkcolumn of the Processor Table. The logarithmic derivative for this argument is contained in theClockJumpDifferenceLookupClientLogDerivativecolumn.
Padding
The last row in the Op Stack Table is taken as the padding template row.
Should the Op Stack Table be empty, the row (clk, shrink_stack, stack_pointer, first_underflow_element) = (0, 0, 16, 0) is used instead.
In the template row, the shrink_stack indicator is set to 2, signifying padding.
The template row is inserted below the last row until the desired padded height is reached.
Memory-Consistency
Memory-consistency follows from two more primitive properties:
- Contiguity of regions of constant memory pointer.
Since in Op Stack Table, the
stack_pointercan change by at most one per cycle, it is possible to enforce a full sorting using AIR constraints. - Correct inner-sorting within contiguous regions. Specifically, the rows within each contiguous region of constant memory pointer should be sorted for clock cycle. This property is established by the clock jump difference Lookup Argument. In a nutshell, every difference of consecutive clock cycles that occurs within one contiguous block of constant memory pointer is shown itself to be a valid clock cycle through a separate cross-table argument.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- The
stack_pointeris the number of available stack registers, i.e., 16. - If the row is not a padding row, the running product for the permutation argument with the Processor Table
rppastarts off having accumulated the first row with respect to challenges 🍋, 🍊, 🍉, and 🫒 and indeterminate 🪤. Otherwise, it is the Permutation Argument’s default initial, i.e., 1. - The logarithmic derivative for the clock jump difference lookup
ClockJumpDifferenceLookupClientLogDerivativeis 0.
Initial Constraints as Polynomials
stack_pointer - 16(shrink_stack - 2)·(rppa - (🪤 - 🍋·clk - 🍊·shrink_stack - 🍉·stack_pointer - 🫒·first_underflow_element))
+ (shrink_stack - 0)·(shrink_stack - 1)·(rppa - 1)ClockJumpDifferenceLookupClientLogDerivative
Consistency Constraints
None.
Transition Constraints
-
- the
stack_pointerincreases by 1, or - the
stack_pointerdoes not change AND thefirst_underflow_elementdoes not change, or - the
stack_pointerdoes not change AND the shrink stack indicatorshrink_stackin the next row is 0.
- the
- If the next row is not a padding row, the running product for the permutation argument with the Processor Table
rppaabsorbs the next row with respect to challenges 🍋, 🍊, 🍉, and 🫒 and indeterminate 🪤. Otherwise, the running product remains unchanged. - If the current row is a padding row, then the next row is a padding row.
- If the next row is not a padding row and the op stack pointer
stack_pointerdoes not change, then the logarithmic derivative for the clock jump difference lookupClockJumpDifferenceLookupClientLogDerivativeaccumulates a factor(clk' - clk)relative to indeterminate 🪞. Otherwise, it remains the unchanged.
Written as Disjunctive Normal Form, the same constraints can be expressed as:
- The
stack_pointerincreases by 1 or thestack_pointerdoes not change. - The
stack_pointerincreases by 1 or thefirst_underflow_elementdoes not change or the shrink stack indicatorshrink_stackin the next row is 0. -
- The next row is a padding row or
rppahas accumulated the next row, and - the next row is not a padding row or
rpparemains unchanged.
- The next row is a padding row or
- The current row is not a padding row or the next row is a padding row.
-
- the
stack_pointerchanges or the next row is a padding row or the logarithmic derivative accumulates a summand, - the
stack_pointerremains unchanged or the logarithmic derivative remains unchanged, and - the next row is not a padding row or the logarithmic derivative remains unchanged.
- the
Transition Constraints as Polynomials
(stack_pointer' - stack_pointer - 1)·(stack_pointer' - stack_pointer)(stack_pointer' - stack_pointer - 1)·(first_underflow_element' - first_underflow_element)·(shrink_stack' - 0)(shrink_stack' - 2)·(rppa' - rppa·(🪤 - 🍋·clk' - 🍊·shrink_stack' - 🍉·stack_pointer' - 🫒first_underflow_element'))
+ (shrink_stack' - 0)·(shrink_stack' - 1)·(rppa' - rppa)(shrink_stack - 0)·(shrink_stack - 1)·(shrink_stack' - 2)(stack_pointer' - stack_pointer - 1)·(shrink_stack' - 2)·((ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative) · (🪞 - clk' + clk) - 1)
+ (stack_pointer' - stack_pointer)·(ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative)
+ (shrink_stack' - 0)·(shrink_stack' - 1)·(ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative)
Terminal Constraints
None.
-
frequently abbreviated as “Op Stack” ↩
Random Access Memory Table
The purpose of the RAM Table is to ensure that the RAM is accessed in a consistent manner.
That is, all mutation of RAM happens explicitly through instruction write_mem,
and any invocations of instruction read_mem return the values last written.
The fundamental principle is identical to that of the Op Stack Table.
The main difference is the absence of a dedicated stack pointer.
Instead, op stack element st0 is used as RAM pointer ram_pointer.
If some RAM address is read from before it is written to, the corresponding value is not determined.
This is one of interfaces for non-deterministic input in Triton VM.
Consecutive reads from any such address always returns the same value (until overwritten via write_mem).
Main Columns
The RAM Table has 7 main columns:
- the cycle counter
clk, - the executed
instruction_type– 0 for “write”, 1 for “read”, 2 for padding rows, - RAM pointer
ram_pointer, - RAM value
ram_value, - helper variable “inverse of
ram_pointerdifference”iord, - Bézout coefficient polynomial coefficient 0
bcpc0, - Bézout coefficient polynomial coefficient 1
bcpc1,
Column iord helps with detecting a change of ram_pointer across two RAM Table rows.
The function of iord is best explained in the context of sorting the RAM Table’s rows, which is what the next section is about.
The Bézout coefficient polynomial coefficients bcpc0 and bcpc1 represent the coefficients of polynomials that are needed for the contiguity argument.
This argument establishes that all regions of constant ram_pointer are contiguous.
Auxiliary Columns
The RAM Table has 6 auxiliary columns:
RunningProductOfRAMP, accumulating next row’sram_pointeras a root wheneverram_pointerchanges between two rows,FormalDerivative, the (evaluated) formal derivative ofRunningProductOfRAMP,BezoutCoefficient0, the (evaluated) polynomial with main columnbcpc0as coefficients,BezoutCoefficient1, the (evaluated) polynomial with main columnbcpc1as coefficients,RunningProductPermArg, the Permutation Argument with the Processor Table, andClockJumpDifferenceLookupClientLogDerivative, part of memory consistency.
Columns RunningProductOfRAMP, FormalDerivative, BezoutCoefficient0, and BezoutCoefficient1 are part of the Contiguity Argument.
Sorting Rows
In the Hash Table, the rows are arranged such that they
- form contiguous regions of
ram_pointer, and - are sorted by cycle counter
clkwithin each such region.
One way to achieve this is to sort by ram_pointer first, clk second.
Coming back to iord:
if the difference between ram_pointer in row and row is 0, then iord in row is 0.
Otherwise, iord in row is the multiplicative inverse of the difference between ram_pointer in row and ram_pointer in row .
In the last row, there being no next row, iord is 0.
An example of the mechanics can be found below.
To increase visual clarity, stack registers holding value “0” are represented by an empty cell.
For illustrative purposes only, we use six stack registers st0 through st5 in the example.
Triton VM has 16 stack registers, st0 through st15.
Processor Table:
| clk | ci | nia | st0 | st1 | st2 | st3 | st4 | st5 |
|---|---|---|---|---|---|---|---|---|
| 0 | push | 20 | ||||||
| 1 | push | 100 | 20 | |||||
| 2 | write_mem | 1 | 100 | 20 | ||||
| 3 | pop | 1 | 101 | |||||
| 4 | push | 5 | ||||||
| 5 | push | 6 | 5 | |||||
| 6 | push | 7 | 6 | 5 | ||||
| 7 | push | 8 | 7 | 6 | 5 | |||
| 8 | push | 9 | 8 | 7 | 6 | 5 | ||
| 9 | push | 42 | 9 | 8 | 7 | 6 | 5 | |
| 10 | write_mem | 5 | 42 | 9 | 8 | 7 | 6 | 5 |
| 11 | pop | 1 | 47 | |||||
| 12 | push | 42 | ||||||
| 13 | read_mem | 1 | 42 | |||||
| 14 | pop | 2 | 41 | 9 | ||||
| 15 | push | 45 | ||||||
| 16 | read_mem | 3 | 45 | |||||
| 17 | pop | 4 | 42 | 8 | 7 | 6 | ||
| 18 | push | 17 | ||||||
| 19 | push | 18 | 17 | |||||
| 20 | push | 19 | 18 | 17 | ||||
| 21 | push | 43 | 19 | 18 | 17 | |||
| 22 | write_mem | 3 | 43 | 19 | 18 | 17 | ||
| 23 | pop | 1 | 46 | |||||
| 24 | push | 46 | ||||||
| 25 | read_mem | 5 | 46 | |||||
| 26 | pop | 1 | 41 | 9 | 19 | 18 | 17 | 5 |
| 27 | pop | 5 | 9 | 19 | 18 | 17 | 5 | |
| 28 | push | 42 | ||||||
| 29 | read_mem | 1 | 42 | |||||
| 30 | pop | 2 | 41 | 9 | ||||
| 31 | push | 100 | ||||||
| 32 | read_mem | 1 | 100 | |||||
| 33 | pop | 2 | 99 | 20 | ||||
| 34 | halt |
RAM Table:
| clk | type | pointer | value | iord |
|---|---|---|---|---|
| 10 | write | 42 | 9 | 0 |
| 13 | read | 42 | 9 | 0 |
| 25 | read | 42 | 9 | 0 |
| 29 | read | 42 | 9 | 1 |
| 10 | write | 43 | 8 | 0 |
| 16 | read | 43 | 8 | 0 |
| 22 | write | 43 | 19 | 0 |
| 25 | read | 43 | 19 | 1 |
| 10 | write | 44 | 7 | 0 |
| 16 | read | 44 | 7 | 0 |
| 22 | write | 44 | 18 | 0 |
| 25 | read | 44 | 18 | 1 |
| 10 | write | 45 | 6 | 0 |
| 16 | read | 45 | 6 | 0 |
| 22 | write | 45 | 17 | 0 |
| 25 | read | 45 | 17 | 1 |
| 10 | write | 46 | 5 | 0 |
| 25 | read | 46 | 5 | |
| 2 | write | 100 | 20 | 0 |
| 32 | read | 100 | 20 | 0 |
Padding
The row used for padding the RAM Table is its last row, with the instruction_type set to 2.
If the RAM Table is empty, the all-zero row with the following modifications is used instead:
instruction_typeis set to 2, andbcpc1is set to 1.
This ensures that the Contiguity Argument works correctly in the absence of any actual contiguous RAM pointer region.
The padding row is inserted below the RAM Table until the desired height is reached.
Row Permutation Argument
The permutation argument with the Processor Table establishes that the RAM Table’s rows correspond to the Processor Table’s sent and received RAM values, at the correct cycle counter and RAM address.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- The first coefficient of the Bézout coefficient polynomial 0
bcpc0is 0. - The Bézout coefficient 0
bc0is 0. - The Bézout coefficient 1
bc1is equal to the first coefficient of the Bézout coefficient polynomialbcpc1. - The running product polynomial
RunningProductOfRAMPstarts with🧼 - ram_pointer. - The formal derivative starts with 1.
- If the first row is not a padding row, the running product for the permutation argument with the Processor Table
RunningProductPermArghas absorbed the first row with respect to challenges 🍍, 🍈, 🍎, and 🌽 and indeterminate 🛋.
Else, the running product for the permutation argument with the Processor TableRunningProductPermArgis 1. - The logarithmic derivative for the clock jump difference lookup
ClockJumpDifferenceLookupClientLogDerivativeis 0.
Initial Constraints as Polynomials
bcpc0bc0bc1 - bcpc1RunningProductOfRAMP - 🧼 + ram_pointerFormalDerivative - 1(RunningProductPermArg - 🛋 - 🍍·clk - 🍈·ram_pointer - 🍎·ram_value - 🌽·instruction_type)·(instruction_type - 2)
(RunningProductPermArg - 1)·(instruction_type - 1)·(instruction_type - 0)ClockJumpDifferenceLookupClientLogDerivative
Consistency Constraints
None.
Transition Constraints
- If the current row is a padding row, then the next row is a padding row.
- The “inverse of
ram_pointerdifference”iordis 0 oriordis the inverse of the difference between current and next row’sram_pointer. - The
ram_pointerchanges oriordis the inverse of the difference between current and next row’sram_pointer. - The
ram_pointerchanges or the next row’sinstruction_typeis “write” or theram_valueremains unchanged. - The
bcbp0changes if and only if theram_pointerchanges. - The
bcbp1changes if and only if theram_pointerchanges. - If the
ram_pointerchanges, theRunningProductOfRAMPaccumulates nextram_pointer.
Otherwise, it remains unchanged. - If the
ram_pointerchanges, theFormalDerivativeupdates under the product rule of differentiation.
Otherwise, it remains unchanged. - If the
ram_pointerchanges, Bézout coefficient 0bc0updates according to the running evaluation rules with respect tobcpc0.
Otherwise, it remains unchanged. - If the
ram_pointerchanges, Bézout coefficient 1bc1updates according to the running evaluation rules with respect tobcpc1.
Otherwise, it remains unchanged. - If the next row is not a padding row, the
RunningProductPermArgaccumulates the next row.
Otherwise, it remains unchanged. - If the
ram_pointerdoes not change and the next row is not a padding row, theClockJumpDifferenceLookupClientLogDerivativeaccumulates the difference ofclk.
Otherwise, it remains unchanged.
Transition Constraints as Polynomials
(instruction_type - 0)·(instruction_type - 1)·(instruction_type' - 2)(iord·(ram_pointer' - ram_pointer) - 1)·iord(iord·(ram_pointer' - ram_pointer) - 1)·(ram_pointer' - ram_pointer)(iord·(ram_pointer' - ram_pointer) - 1)·(instruction_type' - 0)·(ram_value' - ram_value)(iord·(ram_pointer' - ram_pointer) - 1)·(bcpc0' - bcpc0)(iord·(ram_pointer' - ram_pointer) - 1)·(bcpc1' - bcpc1)(iord·(ram_pointer' - ram_pointer) - 1)·(RunningProductOfRAMP' - RunningProductOfRAMP)
+ (ram_pointer' - ram_pointer)·(RunningProductOfRAMP' - RunningProductOfRAMP·(ram_pointer'-🧼))(iord·(ram_pointer' - ram_pointer) - 1)·(FormalDerivative' - FormalDerivative)
+ (ram_pointer' - ram_pointer)·(FormalDerivative' - FormalDerivative·(ram_pointer'-🧼) - RunningProductOfRAMP)(iord·(ram_pointer' - ram_pointer) - 1)·(bc0' - bc0)
+ (ram_pointer' - ram_pointer)·(bc0' - bc0·🧼 - bcpc0')(iord·(ram_pointer' - ram_pointer) - 1)·(bc1' - bc1)
+ (ram_pointer' - ram_pointer)·(bc1' - bc1·🧼 - bcpc1')(RunningProductPermArg' - RunningProductPermArg·(🛋 - 🍍·clk' - 🍈·ram_pointer' - 🍎·ram_value' - 🌽·instruction_type'))·(instruction_type' - 2)
(RunningProductPermArg' - RunningProductPermArg)·(instruction_type - 1)·(instruction_type - 0))(iord·(ram_pointer' - ram_pointer) - 1)·(instruction_type' - 2)·((ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative) · (🪞 - clk' + clk) - 1)
+ (ram_pointer' - ram_pointer)·(ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative)
+ (instruction_type' - 1)·(instruction_type' - 0)·(ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative)
Terminal Constraints
- The Bézout relation holds between
RunningProductOfRAMP,FormalDerivative,bc0, andbc1.
Terminal Constraints as Polynomials
RunningProductOfRAMP·bc0 + FormalDerivative·bc1 - 1
Jump Stack Table
The Jump Stack Memory contains the underflow from the Jump Stack.
Main Columns
The Jump Stack Table consists of 5 columns:
- the cycle counter
clk - current instruction
ci, - the jump stack pointer
jsp, - the last jump’s origin
jso, and - the last jump’s destination
jsd.
| Clock | Current Instruction | Jump Stack Pointer | Jump Stack Origin | Jump Stack Destination |
|---|---|---|---|---|
| - | - | - | - | - |
The rows are sorted by jump stack pointer jsp, then by cycle counter clk.
The column jsd contains the destination of stack-extending jump (call) as well as of the no-stack-change jump (recurse);
the column jso contains the source of the stack-extending jump (call) or equivalently the destination of the stack-shrinking jump (return).
The AIR for this table guarantees that the return address of a single cell of return address memory can change only if there was a call instruction.
An example program, execution trace, and jump stack table are shown below.
Program:
address | instruction |
|---|---|
0x00 | foo |
0x01 | bar |
0x02 | call |
0x03 | 0xA0 |
0x04 | buzz |
0x05 | bar |
0x06 | call |
0x07 | 0xB0 |
0x08 | foo |
0x09 | bar |
| ⋮ | ⋮ |
0xA0 | buzz |
0xA1 | foo |
0xA2 | bar |
0xA3 | return |
0xA4 | foo |
| ⋮ | ⋮ |
0xB0 | foo |
0xB1 | call |
0xB2 | 0xC0 |
0xB3 | return |
0xB4 | bazz |
| ⋮ | ⋮ |
0xC0 | buzz |
0xC1 | foo |
0xC2 | bar |
0xC3 | return |
0xC4 | buzz |
Execution trace:
clk | ip | ci | nia | jsp | jso | jsd | jump stack |
|---|---|---|---|---|---|---|---|
| 0 | 0x00 | foo | bar | 0 | 0x00 | 0x00 | [ ] |
| 1 | 0x01 | bar | call | 0 | 0x00 | 0x00 | [ ] |
| 2 | 0x02 | call | 0xA0 | 0 | 0x00 | 0x00 | [ ] |
| 3 | 0xA0 | buzz | foo | 1 | 0x04 | 0xA0 | [(0x04, 0xA0)] |
| 4 | 0xA1 | foo | bar | 1 | 0x04 | 0xA0 | [(0x04, 0xA0)] |
| 5 | 0xA2 | bar | return | 1 | 0x04 | 0xA0 | [(0x04, 0xA0)] |
| 6 | 0xA3 | return | foo | 1 | 0x04 | 0xA0 | [(0x04, 0xA0)] |
| 7 | 0x04 | buzz | bar | 0 | 0x00 | 0x00 | [ ] |
| 8 | 0x05 | bar | call | 0 | 0x00 | 0x00 | [ ] |
| 9 | 0x06 | call | 0xB0 | 0 | 0x00 | 0x00 | [ ] |
| 10 | 0xB0 | foo | call | 1 | 0x08 | 0xB0 | [(0x08, 0xB0)] |
| 11 | 0xB1 | call | 0xC0 | 1 | 0x08 | 0xB0 | [(0x08, 0xB0)] |
| 12 | 0xC0 | buzz | foo | 2 | 0xB3 | 0xC0 | [(0x08, 0xB0), (0xB3, 0xC0)] |
| 13 | 0xC1 | foo | bar | 2 | 0xB3 | 0xC0 | [(0x08, 0xB0), (0xB3, 0xC0)] |
| 14 | 0xC2 | bar | return | 2 | 0xB3 | 0xC0 | [(0x08, 0xB0), (0xB3, 0xC0)] |
| 15 | 0xC3 | return | buzz | 2 | 0xB3 | 0xC0 | [(0x08, 0xB0), (0xB3, 0xC0)] |
| 16 | 0xB3 | return | bazz | 1 | 0x08 | 0xB0 | [(0x08, 0xB0)] |
| 17 | 0x08 | foo | bar | 0 | 0x00 | 0x00 | [ ] |
Jump Stack Table:
clk | ci | jsp | jso | jsd |
|---|---|---|---|---|
| 0 | foo | 0 | 0x00 | 0x00 |
| 1 | bar | 0 | 0x00 | 0x00 |
| 2 | call | 0 | 0x00 | 0x00 |
| 7 | buzz | 0 | 0x00 | 0x00 |
| 8 | bar | 0 | 0x00 | 0x00 |
| 9 | call | 0 | 0x00 | 0x00 |
| 17 | foo | 0 | 0x00 | 0x00 |
| 3 | buzz | 1 | 0x04 | 0xA0 |
| 4 | foo | 1 | 0x04 | 0xA0 |
| 5 | bar | 1 | 0x04 | 0xA0 |
| 6 | return | 1 | 0x04 | 0xA0 |
| 10 | foo | 1 | 0x08 | 0xB0 |
| 11 | call | 1 | 0x08 | 0xB0 |
| 16 | return | 1 | 0x08 | 0xB0 |
| 12 | buzz | 2 | 0xB3 | 0xC0 |
| 13 | foo | 2 | 0xB3 | 0xC0 |
| 14 | bar | 2 | 0xB3 | 0xC0 |
| 15 | return | 2 | 0xB3 | 0xC0 |
Auxiliary Columns
The Jump Stack Table has 2 auxiliary columns, rppa and ClockJumpDifferenceLookupClientLogDerivative.
- A Permutation Argument establishes that the rows of the Jump Stack Table match with the rows in the Processor Table.
The running product for this argument is contained in the
rppacolumn. - In order to achieve memory consistency, a Lookup Argument shows that all clock jump differences are contained in the
clkcolumn of the Processor Table. The logarithmic derivative for this argument is contained in theClockJumpDifferenceLookupClientLogDerivativecolumn.
Padding
A padding row is a direct copy of the Jump Stack Table’s row with the highest value for column clk, called template row, with the exception of the cycle count column clk.
In a padding row, the value of column clk is 1 greater than the value of column clk in the template row.
The padding row is inserted right below the template row.
These steps are repeated until the desired padded height is reached.
In total, above steps ensure that the Permutation Argument between the Jump Stack Table and the Processor Table holds up.
Memory-Consistency
Memory-consistency follows from two more primitive properties:
- Contiguity of regions of constant memory pointer.
Since the memory pointer for the Jump Stack table,
jspcan change by at most one per cycle, it is possible to enforce a full sorting using AIR constraints. - Correct inner-sorting within contiguous regions. Specifically, the rows within each contiguous region of constant memory pointer should be sorted for clock cycle. This property is established by the clock jump difference Lookup Argument. In a nutshell, every difference of consecutive clock cycles that occurs within one contiguous block of constant memory pointer is shown itself to be a valid clock cycle through a separate cross-table argument.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- Cycle count
clkis 0. - Jump Stack Pointer
jspis 0. - Jump Stack Origin
jsois 0. - Jump Stack Destination
jsdis 0. - The running product for the permutation argument with the Processor Table
rppahas absorbed the first row with respect to challenges 🍇, 🍅, 🍌, 🍏, and 🍐 and indeterminate 🧴. - The running product of clock jump differences
ClockJumpDifferenceLookupClientLogDerivativeis 0.
Initial Constraints as Polynomials
clkjspjsojsdrppa - (🧴 - 🍇·clk - 🍅·ci - 🍌·jsp - 🍏·jso - 🍐·jsd)ClockJumpDifferenceLookupClientLogDerivative
Consistency Constraints
None.
Transition Constraints
- The jump stack pointer
jspincreases by 1, or - (
jspdoes not change andjsodoes not change andjsddoes not change and the cycle counterclkincreases by 1), or - (
jspdoes not change andjsodoes not change andjsddoes not change and the current instructionciiscall), or - (
jspdoes not change and the current instructionciisreturn), or - (
jspdoes not change and the current instructionciisrecurse_or_return). - The running product for the permutation argument
rppaabsorbs the next row with respect to challenges 🍇, 🍅, 🍌, 🍏, and 🍐 and indeterminate 🧴. - If the jump stack pointer
jspdoes not change, then the logarithmic derivative for the clock jump difference lookupClockJumpDifferenceLookupClientLogDerivativeaccumulates a factor(clk' - clk)relative to indeterminate 🪞. Otherwise, it remains the same.
Written as Disjunctive Normal Form, the same constraints can be expressed as:
- The jump stack pointer
jspincreases by 1 or the jump stack pointerjspdoes not change - The jump stack pointer
jspincreases by 1 or the jump stack originjsodoes not change or current instructionciisreturnorrecurse_or_return - The jump stack pointer
jspincreases by 1 or the jump stack destinationjsddoes not change or current instructionciisreturnorrecurse_or_return - The jump stack pointer
jspincreases by 1 or the cycle countclkincreases by 1 or current instructionciiscallor current instructionciisreturnorrecurse_or_return rppa' - rppa·(🧴 - 🍇·clk' - 🍅·ci' - 🍌·jsp' - 🍏·jso' - 🍐·jsd')-
- the
jspchanges or the logarithmic derivative accumulates a summand, and - the
jspdoes not change or the logarithmic derivative does not change.
- the
Transition Constraints as Polynomials
(jsp' - (jsp + 1))·(jsp' - jsp)(jsp' - (jsp + 1))·(jso' - jso)·(ci - op_code(return))(jsp' - (jsp + 1))·(jsd' - jsd)·(ci - op_code(return))(jsp' - (jsp + 1))·(clk' - (clk + 1))·(ci - op_code(call))·(ci - op_code(return))clk_di·(jsp' - jsp - 1)·(1 - clk_di·(clk' - clk - one))(clk' - clk - one)·(jsp' - jsp - 1)·(1 - clk_di·(clk' - clk - one))rppa' - rppa·(🧴 - 🍇·clk' - 🍅·ci' - 🍌·jsp' - 🍏·jso' - 🍐·jsd')(jsp' - (jsp + 1))·((ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative) · (🪞 - clk' + clk) - 1)
+ (jsp' - jsp)·(ClockJumpDifferenceLookupClientLogDerivative' - ClockJumpDifferenceLookupClientLogDerivative)
Terminal Constraints
None.
Hash Table
The instruction hash hashes the Op Stack’s 10 top-most elements in one cycle.
Similarly, the Sponge instructions sponge_init, sponge_absorb, and sponge_squeeze also all complete in one cycle.
The main processor achieves this by using a hash coprocessor.
The Hash Table is part of the arithmetization of that coprocessor, the other two parts being the Cascade Table and the Lookup Table.
In addition to accelerating these hashing instructions, the Hash Table helps with program attestation by hashing the program.
Note: the Hash Table is not “aware” of instruction sponge_absorb_mem.
Instead, the processor requests a “regular” sponge_absorb from the Hash Table, fetching the to-be-absorbed elements from RAM instead of the stack.
The arithmetization for instruction hash, the Sponge instructions sponge_init, sponge_absorb, and sponge_squeeze, and for program hashing are quite similar.
The main differences are in updates to the state registers between executions of the pseudo-random permutation used in Triton VM, the permutation of Tip5.
A summary of the four instructions’ mechanics:
- Instruction
hash- sets all the hash coprocessor’s rate registers (
state_0throughstate_9) to equal the processor’s stack registersstate_0throughstate_9, - sets all the hash coprocessor’s capacity registers (
state_10throughstate_15) to 1, - executes the 5 rounds of the Tip5 permutation,
- overwrites the processor’s stack registers
state_0throughstate_4with 0, and - overwrites the processor’s stack registers
state_5throughstate_9with the hash coprocessor’s registersstate_0throughstate_4.
- sets all the hash coprocessor’s rate registers (
- Instruction
sponge_init- sets all the hash coprocessor’s registers (
state_0throughstate_15) to 0.
- sets all the hash coprocessor’s registers (
- Instruction
sponge_absorb- overwrites the hash coprocessor’s rate registers (
state_0throughstate_9) with the processor’s stack registersstate_0throughstate_9, and - executes the 5 rounds of the Tip5 permutation.
- overwrites the hash coprocessor’s rate registers (
- Instruction
sponge_squeeze- overwrites the processor’s stack registers
state_0throughstate_9with the hash coprocessor’s rate registers (state_0throughstate_9), and - executes the 5 rounds of the Tip5 permutation.
- overwrites the processor’s stack registers
Program hashing happens in the initialization phase of Triton VM.
The to-be-executed program has no control over it.
Program hashing is mechanically identical to performing instruction sponge_absorb as often as is necessary to hash the entire program.
A notable difference is the source of the to-be-absorbed elements:
they come from program memory, not the processor (which is not running yet).
Once all instructions have been absorbed, the resulting digest is checked against the publicly claimed digest.
Due to the various similar but distinct tasks of the Hash Table, it has an explicit Mode register.
The four separate modes are program_hashing, sponge, hash, and pad, and they evolve in that order.
Changing the mode is only possible when the permutation has been applied in full, i.e., when the round number is 5.
Once mode pad is reached, it is not possible to change the mode anymore.
It is not possible to skip mode program_hashing:
the program is always hashed.
Skipping any or all of the modes sponge, hash, or pad is possible in principle:
- if no Sponge instructions are executed, mode
spongewill be skipped, - if no
hashinstruction is executed, modehashwill be skipped, and - if the Hash Table does not require any padding, mode
padwill be skipped.
The distinct modes translate into distinct sections in the Hash Table, which are recorded in order:
First, the entire Sponge’s transition of hashing the program is recorded.
Then, the Hash Table records all Sponge instructions in the order the processor executed them.
Then, the Hash Table records all hash instructions in the order the processor executed them.
Lastly, as many padding rows as necessary are inserted.
In total, this separation allows the processor to execute hash instructions without affecting the Sponge’s state, and keeps program hashing independent from both.
Note that state_0 through state_3, corresponding to those states that are being split-and-looked-up in the Tip5 permutation, are not stored as a single field element.
Instead, four limbs “highest”, “mid high”, “mid low”, and “lowest” are recorded in the Hash Table.
This (basically) corresponds to storing the result of .
In the Hash Table, the resulting limbs are 16 bit wide, and hence, there are only 4 limbs;
the split into 8-bit limbs happens in the Cascade Table.
For convenience, this document occasionally refers to those states as if they were a single register.
This is an alias for
.
Main Columns
The Hash Table has 67 main columns:
- The
Modeindicator, as described above. It takes value- for mode
program_hashing, - for mode
sponge, - for mode
hash, and - for mode
pad.
- for mode
- Current instruction
CI, holding the instruction the processor is currently executing. This column is only relevant for modesponge. - Round number indicator
round_no, which can be one of . The Tip5 permutation has 5 rounds, indexed . The round number 5 indicates that the Tip5 permutation has been applied in full. - 16 columns
state_i_highest_lkin,state_i_mid_high_lkin,state_i_mid_low_lkin,state_i_lowest_lkinfor the to-be-looked-up value ofstate_0throughstate_4, each of which holds one 16-bit wide limb. - 16 columns
state_i_highest_lkout,state_i_mid_high_lkout,state_i_mid_low_lkout,state_i_lowest_lkoutfor the looked-up value ofstate_0throughstate_4, each of which holds one 16-bit wide limb. - 12 columns
state_5throughstate_15. - 4 columns
state_i_investablishing correct decomposition ofstate_0_*_lkinthroughstate_3_*_lkininto 16-bit wide limbs. - 16 columns
constant_i, which hold the round constant for the round indicated byRoundNumber, or 0 if no round with this round number exists.
Auxiliary Columns
The Hash Table has 20 auxiliary columns:
RunningEvaluationReceiveChunkfor the Evaluation Argument for copying chunks of size from the Program Table. Relevant for program attestation.RunningEvaluationHashInputfor the Evaluation Argument for copying the input to the hash function from the processor to the hash coprocessor,RunningEvaluationHashDigestfor the Evaluation Argument for copying the hash digest from the hash coprocessor to the processor,RunningEvaluationSpongefor the Evaluation Argument for copying the 10 next to-be-absorbed elements from the processor to the hash coprocessor or the 10 next squeezed elements from the hash coprocessor to the processor, depending on the instruction,- 16 columns
state_i_limb_LookupClientLogDerivative(foriandlimbhighest,mid_high,mid_low,lowest) establishing correct lookup of the respective limbs in the Cascade Table.
Padding
Each padding row is the all-zero row with the exception of
CI, which is the opcode of instructionhash,state_i_invfori, which is , andconstant_ifori, which is theith constant for round 0.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- The
Modeisprogram_hashing. - The round number is 0.
RunningEvaluationReceiveChunkhas absorbed the first chunk of instructions with respect to indeterminate 🪣.RunningEvaluationHashInputis 1.RunningEvaluationHashDigestis 1.RunningEvaluationSpongeis 1.- For
iandlimbhighest,mid_high,mid_low,lowest:
state_i_limb_LookupClientLogDerivativehas accumulatedstate_i_limb_lkinandstate_i_limb_lkoutwith respect to challenges 🍒, 🍓 and indeterminate 🧺.
Initial Constraints as Polynomials
Mode - 1round_noRunningEvaluationReceiveChunk - 🪣 - (🪑^10 + state_0·🪑^9 + state_1·🪑^8 + state_2·🪑^7 + state_3·🪑^6 + state_4·🪑^5 + state_5·🪑^4 + state_6·🪑^3 + state_7·🪑^2 + state_8·🪑 + state_9)RunningEvaluationHashInput - 1RunningEvaluationHashDigest - 1RunningEvaluationSponge - 1- For
iandlimbhighest,mid_high,mid_low,lowest:
state_i_limb_LookupClientLogDerivative·(🧺 - 🍒·state_i_limb_lkin - 🍓·state_i_limb_lkout) - 1
Consistency Constraints
- The
Modeis a valid mode, i.e., . - If the
Modeisprogram_hashing,hash, orpad, then the current instruction is the opcode ofhash. - If the
Modeissponge, then the current instruction is a Sponge instruction. - If the
Modeispad, then theround_nois 0. - If the current instruction
CIissponge_init, then theround_nois 0. - For
i: If the current instructionCIissponge_init, then registerstate_iis 0. (Note: the remaining registers, corresponding to the rate, are guaranteed to be 0 through the Evaluation Argument “Sponge” with the processor.) - For
i: If the round number is 0 and the currentModeishash, then registerstate_iis 1. - For
i: ensure that decomposition ofstate_iis unique. That is, if both high limbs ofstate_iare the maximum value, then both low limbs are 01. To make the corresponding polynomials low degree, registerstate_i_invholds the inverse-or-zero of the re-composed highest two limbs ofstate_isubtracted from their maximum value. Letstate_i_hi_limbs_minus_2_pow_32be an alias for that difference:state_i_hi_limbs_minus_2_pow_32state_i_highest_lk_instate_i_mid_high_lk_in.- If the two high limbs of
state_iare both the maximum possible value, then the two low limbs ofstate_iare both 0. - The
state_i_invis the inverse ofstate_i_hi_limbs_minus_2_pow_32orstate_i_invis 0. - The
state_i_invis the inverse ofstate_i_hi_limbs_minus_2_pow_32orstate_i_hi_limbs_minus_2_pow_32is 0.
- If the two high limbs of
- The round constants adhere to the specification of Tip5.
Consistency Constraints as Polynomials
(Mode - 0)·(Mode - 1)·(Mode - 2)·(Mode - 3)(Mode - 2)·(CI - opcode(hash))(Mode - 0)·(Mode - 1)·(Mode - 3)
·(CI - opcode(sponge_init))·(CI - opcode(sponge_absorb))·(CI - opcode(sponge_squeeze))(Mode - 1)·(Mode - 2)·(Mode - 3)·(round_no - 0)(CI - opcode(hash))·(CI - opcode(sponge_absorb))·(CI - opcode(sponge_squeeze))·(round_no - 0)- For
i:
·(CI - opcode(hash))·(CI - opcode(sponge_absorb))·(CI - opcode(sponge_squeeze))
·(state_i - 0) - For
i:
(round_no - 1)·(round_no - 2)·(round_no - 3)·(round_no - 4)·(round_no - 5)
·(Mode - 0)·(Mode - 1)·(Mode - 2)
·(state_i - 1) - For
i: definestate_i_hi_limbs_minus_2_pow_32 := 2^32 - 1 - 2^16·state_i_highest_lk_in - state_i_mid_high_lk_in.(1 - state_i_inv · state_i_hi_limbs_minus_2_pow_32)·(2^16·state_i_mid_low_lk_in + state_i_lowest_lk_in)(1 - state_i_inv · state_i_hi_limbs_minus_2_pow_32)·state_i_inv(1 - state_i_inv · state_i_hi_limbs_minus_2_pow_32)·state_i_hi_limbs_minus_2_pow_32
Transition Constraints
- If the
round_nois 5, then theround_noin the next row is 0. - If the
Modeis notpadand the current instructionCIis notsponge_initand theround_nois not 5, then theround_noincrements by 1. - If the
Modein the next row isprogram_hashingand theround_noin the next row is 0, then receive a chunk of instructions with respect to challenges 🪣 and 🪑. - If the
Modechanges fromprogram_hashing, then the Evaluation Argument ofstate_0throughstate_4with respect to indeterminate 🥬 equals the public program digest challenge, 🫑. - If the
Modeisprogram_hashingand theModein the next row issponge, then the current instruction in the next row issponge_init. - If the
round_nois not 5 and the current instructionCIis notsponge_init, then the current instruction does not change. - If the
round_nois not 5 and the current instructionCIis notsponge_init, then theModedoes not change. - If the
Modeissponge, then theModein the next row isspongeorhashorpad. - If the
Modeishash, then theModein the next row ishashorpad. - If the
Modeispad, then theModein the next row ispad. - If the
round_noin the next row is 0 and theModein the next row is eitherprogram_hashingorspongeand the instruction in the next row is eithersponge_absorborsponge_init, then the capacity’s state registers don’t change. - If the
round_noin the next row is 0 and the current instruction in the next row issponge_squeeze, then none of the state registers change. - If the
round_noin the next row is 0 and theModein the next row ishash, thenRunningEvaluationHashInputaccumulates the next row with respect to challenges 🧄₀ through 🧄₉ and indeterminate 🚪. Otherwise, it remains unchanged. - If the
round_noin the next row is 5 and theModein the next row ishash, thenRunningEvaluationHashDigestaccumulates the next row with respect to challenges 🧄₀ through 🧄₄ and indeterminate 🪟. Otherwise, it remains unchanged. - If the
round_noin the next row is 0 and theModein the next row issponge, thenRunningEvaluationSpongeaccumulates the next row with respect to challenges 🧅 and 🧄₀ through 🧄₉ and indeterminate 🧽. Otherwise, it remains unchanged. - For
iandlimbhighest,mid_high,mid_low,lowest:
If the next round number is not 5 and themodein the next row is notpadand the current instructionCIin the next row is notsponge_init, thenstate_i_limb_LookupClientLogDerivativehas accumulatedstate_i_limb_lkin'andstate_i_limb_lkout'with respect to challenges 🍒, 🍓 and indeterminate 🧺. Otherwise,state_i_limb_LookupClientLogDerivativeremains unchanged. - For
r:
If theround_noisr, thestateregisters adhere to the rules of applying roundrof the Tip5 permutation.
Transition Constraints as Polynomials
(round_no - 0)·(round_no - 1)·(round_no - 2)·(round_no - 3)·(round_no - 4)·(round_no' - 0)(Mode - 0)·(round_no - 5)·(CI - opcode(sponge_init))·(round_no' - round_no - 1)RunningEvaluationReceiveChunk' - 🪣·RunningEvaluationReceiveChunk - (🪑^10 + state_0·🪑^9 + state_1·🪑^8 + state_2·🪑^7 + state_3·🪑^6 + state_4·🪑^5 + state_5·🪑^4 + state_6·🪑^3 + state_7·🪑^2 + state_8·🪑 + state_9)(Mode - 0)·(Mode - 2)·(Mode - 3)·(Mode' - 1)·(🥬^5 + state_0·🥬^4 + state_1·🥬^3 + state_2·🥬^2 + state_3·🥬^1 + state_4 - 🫑)(Mode - 0)·(Mode - 2)·(Mode - 3)·(Mode' - 2)·(CI' - opcode(sponge_init))(round_no - 5)·(CI - opcode(sponge_init))·(CI' - CI)(round_no - 5)·(CI - opcode(sponge_init))·(Mode' - Mode)(Mode - 0)·(Mode - 1)·(Mode - 3)·(Mode' - 0)·(Mode' - 2)·(Mode' - 3)(Mode - 0)·(Mode - 1)·(Mode - 2)·(Mode' - 0)·(Mode' - 3)(Mode - 1)·(Mode - 2)·(Mode - 3)·(Mode' - 0)(round_no' - 1)·(round_no' - 2)·(round_no' - 3)·(round_no' - 4)·(round_no' - 5)
·(Mode' - 3)·(Mode' - 0)
·(CI' - opcode(sponge_init))
·(🧄₁₀·(state_10' - state_10) + 🧄₁₁·(state_11' - state_11) + 🧄₁₂·(state_12' - state_12) + 🧄₁₃·(state_13' - state_13) + 🧄₁₄·(state_14' - state_14) + 🧄₁₅·(state_15' - state_15))(round_no' - 1)·(round_no' - 2)·(round_no' - 3)·(round_no' - 4)·(round_no' - 5)
·(CI' - opcode(hash))·(CI' - opcode(sponge_init))·(CI' - opcode(sponge_absorb))
·(🧄₀·(state_0' - state_0) + 🧄₁·(state_1' - state_1) + 🧄₂·(state_2' - state_2) + 🧄₃·(state_3' - state_3) + 🧄₄·(state_4' - state_4)
+ 🧄₅·(state_5' - state_5) + 🧄₆·(state_6' - state_6) + 🧄₇·(state_7' - state_7) + 🧄₈·(state_8' - state_8) + 🧄₉·(state_9' - state_9)
+ 🧄₁₀·(state_10' - state_10) + 🧄₁₁·(state_11' - state_11) + 🧄₁₂·(state_12' - state_12) + 🧄₁₃·(state_13' - state_13) + 🧄₁₄·(state_14' - state_14) + 🧄₁₅·(state_15' - state_15))(round_no' - 0)·(round_no' - 1)·(round_no' - 2)·(round_no' - 3)·(round_no' - 4)
·(RunningEvaluationHashInput' - 🚪·RunningEvaluationHashInput - 🧄₀·state_0' - 🧄₁·state_1' - 🧄₂·state_2' - 🧄₃·state_3' - 🧄₄·state_4' - 🧄₅·state_5' - 🧄₆·state_6' - 🧄₇·state_7' - 🧄₈·state_8' - 🧄₉·state_9')
+ (round_no' - 0)·(RunningEvaluationHashInput' - RunningEvaluationHashInput)
+ (Mode' - 3)·(RunningEvaluationHashInput' - RunningEvaluationHashInput)(round_no' - 0)·(round_no' - 1)·(round_no' - 2)·(round_no' - 3)·(round_no' - 4)
·(Mode' - 0)·(Mode' - 1)·(Mode' - 2)
·(RunningEvaluationHashDigest' - 🪟·RunningEvaluationHashDigest - 🧄₀·state_0' - 🧄₁·state_1' - 🧄₂·state_2' - 🧄₃·state_3' - 🧄₄·state_4')
+ (round_no' - 5)·(RunningEvaluationHashDigest' - RunningEvaluationHashDigest)
+ (Mode' - 3)·(RunningEvaluationHashDigest' - RunningEvaluationHashDigest)(round_no' - 1)·(round_no' - 2)·(round_no' - 3)·(round_no' - 4)·(round_no' - 5)
·(CI' - opcode(hash))
·(RunningEvaluationSponge' - 🧽·RunningEvaluationSponge - 🧅·CI' - 🧄₀·state_0' - 🧄₁·state_1' - 🧄₂·state_2' - 🧄₃·state_3' - 🧄₄·state_4' - 🧄₅·state_5' - 🧄₆·state_6' - 🧄₇·state_7' - 🧄₈·state_8' - 🧄₉·state_9')
+ (RunningEvaluationSponge' - RunningEvaluationSponge)·(round_no' - 0)
+ (RunningEvaluationSponge' - RunningEvaluationSponge)·(CI' - opcode(sponge_init))·(CI' - opcode(sponge_absorb))·(CI' - opcode(sponge_squeeze))- For
iandlimbhighest,mid_high,mid_low,lowest:
(round_no' - 5)·(Mode' - 0)·(CI' - opcode(sponge_init))·((state_i_limb_LookupClientLogDerivative' - state_i_limb_LookupClientLogDerivative)·(🧺 - 🍒·state_i_limb_lkin' - 🍓·state_i_limb_lkout') - 1)
+ (round_no' - 0)·(round_no' - 1)·(round_no' - 2)·(round_no' - 3)·(round_no' - 4)
·(state_i_limb_LookupClientLogDerivative' - state_i_limb_LookupClientLogDerivative)
+ (CI' - opcode(hash))·(CI' - opcode(sponge_absorb))·(CI' - opcode(sponge_squeeze))
·(state_i_limb_LookupClientLogDerivative' - state_i_limb_LookupClientLogDerivative) - The remaining constraints are left as an exercise to the reader. For hints, see the Tip5 paper.
Terminal Constraints
- If the
Modeisprogram_hashing, then the Evaluation Argument ofstate_0throughstate_4with respect to indeterminate 🥬 equals the public program digest challenge, 🫑. - If the
Modeis notpadand the current instructionCIis notsponge_init, then theround_nois 5.
Terminal Constraints as Polynomials
🥬^5 + state_0·🥬^4 + state_1·🥬^3 + state_2·🥬^2 + state_3·🥬 + state_4 - 🫑(Mode - 0)·(CI - opcode(sponge_init))·(round_no - 5)
-
This is a special property of the Oxfoi prime. ↩
Cascade Table
The Cascade Table helps arithmetizing the lookups necessary for the split-and-lookup S-box used in the Tip5 permutation. The main idea is to allow the Hash Table to look up limbs that are 16 bit wide even though the S-box is defined over limbs that are 8 bit wide. The Cascade Table facilitates the translation of limb widths. For the actual lookup of the 8-bit limbs, the Lookup Table is used. For a more detailed explanation and in-depth analysis, see the Tip5 paper.
Main Columns
The Cascade Table has 6 main columns:
| name | description |
|---|---|
IsPadding | Indicator for padding rows. |
LookInHi | The more significant bits of the lookup input. |
LookInLo | The less significant bits of the lookup input. |
LookOutHi | The more significant bits of the lookup output. |
LookOutLo | The less significant bits of the lookup output. |
LookupMultiplicity | The number of times the value is looked up by the Hash Table. |
Auxiliary Columns
The Cascade Table has 2 auxiliary columns:
HashTableServerLogDerivative, the (running sum of the) logarithmic derivative for the Lookup Argument with the Hash Table. In every row, the sum accumulatesLookupMultiplicity / (🧺 - Combo)where 🧺 is a verifier-supplied challenge andCombois the weighted sum ofLookInHi · 2^8 + LookInLoandLookOutHi · 2^8 + LookOutLowith weights 🍒 and 🍓 supplied by the verifier.LookupTableClientLogDerivative, the (running sum of the) logarithmic derivative for the Lookup Argument with the Lookup Table. In every row, the sum accumulates the two summands1 / combo_hiwherecombo_hiis the verifier-weighted combination ofLookInHiandLookOutHi, and1 / combo_lowherecombo_lois the verifier-weighted combination ofLookInLoandLookOutLo.
Padding
Each padding row is the all-zero row with the exception of IsPadding, which is 1.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- If the first row is not a padding row, then
HashTableServerLogDerivativehas accumulated the first row with respect to challenges 🍒 and 🍓 and indeterminate 🧺. Else,HashTableServerLogDerivativeis 0. - If the first row is not a padding row, then
LookupTableClientLogDerivativehas accumulated the first row with respect to challenges 🥦 and 🥒 and indeterminate 🪒. Else,LookupTableClientLogDerivativeis 0.
Initial Constraints as Polynomials
(1 - IsPadding)·(HashTableServerLogDerivative·(🧺 - 🍒·(2^8·LookInHi + LookInLo) - 🍓·(2^8 · LookOutHi + LookOutLo)) - LookupMultiplicity)
+ IsPadding · HashTableServerLogDerivative(1 - IsPadding)·(LookupTableClientLogDerivative·(🪒 - 🥦·LookInLo - 🥒·LookOutLo)·(🪒 - 🥦·LookInHi - 🥒·LookOutHi) - 2·🪒 + 🥦·(LookInLo + LookInHi) + 🥒·(LookOutLo + LookOutHi))
+ IsPadding·LookupTableClientLogDerivative
Consistency Constraints
IsPaddingis 0 or 1.
Consistency Constraints as Polynomials
IsPadding·(1 - IsPadding)
Transition Constraints
- If the current row is a padding row, then the next row is a padding row.
- If the next row is not a padding row, then
HashTableServerLogDerivativeaccumulates the next row with respect to challenges 🍒 and 🍓 and indeterminate 🧺. Else,HashTableServerLogDerivativeremains unchanged. - If the next row is not a padding row, then
LookupTableClientLogDerivativeaccumulates the next row with respect to challenges 🥦 and 🥒 and indeterminate 🪒. Else,LookupTableClientLogDerivativeremains unchanged.
Transition Constraints as Polynomials
IsPadding·(1 - IsPadding')(1 - IsPadding')·((HashTableServerLogDerivative' - HashTableServerLogDerivative)·(🧺 - 🍒·(2^8·LookInHi' + LookInLo') - 🍓·(2^8 · LookOutHi' + LookOutLo')) - LookupMultiplicity')
+ IsPadding'·(HashTableServerLogDerivative' - HashTableServerLogDerivative)(1 - IsPadding')·((LookupTableClientLogDerivative' - LookupTableClientLogDerivative)·(🪒 - 🥦·LookInLo' - 🥒·LookOutLo')·(🪒 - 🥦·LookInHi' - 🥒·LookOutHi') - 2·🪒 + 🥦·(LookInLo' + LookInHi') + 🥒·(LookOutLo' + LookOutHi'))
+ IsPadding'·(LookupTableClientLogDerivative' - LookupTableClientLogDerivative)
Terminal Constraints
None.
Lookup Table
The Lookup Table helps arithmetizing the lookups necessary for the split-and-lookup S-box used in the Tip5 permutation. It works in tandem with the Cascade Table. In the language of the Tip5 paper, it is a “narrow lookup table.” This means it is always fully populated, independent of the actual number of lookups.
Correct creation of the Lookup Table is guaranteed through a public-facing Evaluation Argument: after sampling some challenge , the verifier computes the terminal of the Evaluation Argument over the list of all the expected lookup values with respect to challenge . The equality of this verifier-supplied terminal against the similarly computed, in-table part of the Evaluation Argument is checked by the Lookup Table’s terminal constraint.
Main Columns
The Lookup Table has 4 main columns:
| name | description |
|---|---|
IsPadding | Indicator for padding rows. |
LookIn | The lookup input. |
LookOut | The lookup output. |
LookupMultiplicity | The number of times the value is looked up. |
Auxiliary Columns
The Lookup Table has 2 auxiliary columns:
CascadeTableServerLogDerivative, the (running sum of the) logarithmic derivative for the Lookup Argument with the Cascade Table. In every row, accumulates the summandLookupMultiplicity / CombowhereCombois the verifier-weighted combination ofLookInandLookOut.PublicEvaluationArgument, the running sum for the public evaluation argument of the Lookup Table. In every row, accumulatesLookOut.
Padding
Each padding row is the all-zero row with the exception of IsPadding, which is 1.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
LookInis 0.CascadeTableServerLogDerivativehas accumulated the first row with respect to challenges 🍒 and 🍓 and indeterminate 🧺.PublicEvaluationArgumenthas accumulated the firstLookOutwith respect to indeterminate 🧹.
Initial Constraints as Polynomials
LookInCascadeTableServerLogDerivative·(🧺 - 🍒·LookIn - 🍓·LookOut) - LookupMultiplicityPublicEvaluationArgument - 🧹 - LookOut
Consistency Constraints
IsPaddingis 0 or 1.
Consistency Constraints as Polynomials
IsPadding·(1 - IsPadding)
Transition Constraints
- If the current row is a padding row, then the next row is a padding row.
- If the next row is not a padding row,
LookInincrements by 1. Else,LookInis 0. - If the next row is not a padding row,
CascadeTableServerLogDerivativeaccumulates the next row with respect to challenges 🍒 and 🍓 and indeterminate 🧺. Else,CascadeTableServerLogDerivativeremains unchanged. - If the next row is not a padding row,
PublicEvaluationArgumentaccumulates the nextLookOutwith respect to indeterminate 🧹. Else,PublicEvaluationArgumentremains unchanged.
Transition Constraints as Polynomials
IsPadding·(1 - IsPadding')((1 - IsPadding')·(LookIn' - LookIn - 1))
+ IsPadding'·LookIn'(1 - IsPadding')·((CascadeTableServerLogDerivative' - CascadeTableServerLogDerivative)·(🧺 - 🍒·LookIn' - 🍓·LookOut') - LookupMultiplicity')
+ IsPadding'·(CascadeTableServerLogDerivative' - CascadeTableServerLogDerivative)(1 - IsPadding')·(PublicEvaluationArgument' - 🧹·PublicEvaluationArgument - LookOut')
+ IsPadding'·(PublicEvaluationArgument' - PublicEvaluationArgument)
Terminal Constraints
PublicEvaluationArgumentmatches verifier-supplied challenge 🪠.
Terminal Constraints as Polynomials
PublicEvaluationArgument- 🪠
U32 Table
The U32 Operations Table arithmetizes the coprocessor for “difficult” 32-bit unsigned integer operations.
The two inputs to the U32 Operations Table are left-hand side (LHS) and right-hand side (RHS), usually corresponding to the processor’s st0 and st1, respectively.
(For more details see the arithmetization of the specific u32 instructions further below.)
To allow efficient arithmetization, a u32 instruction’s result is constructed using multiple rows.
The collection of rows arithmetizing the execution of one instruction is called a section.
The U32 Table’s sections are independent of each other.
The processor’s current instruction CI is recorded within the section and dictates its arithmetization.
Crucially, the rows of the U32 table are independent of the processor’s clock. Hence, the result of the instruction can be transferred into the processor within one clock cycle.
Main Columns
| name | description |
|---|---|
CopyFlag | The row to be copied between processor and u32 coprocessor. Marks the beginning of a section. |
CI | Current instruction, the instruction the processor is currently executing. |
Bits | The number of bits that LHS and RHS have already been shifted by. |
BitsMinus33Inv | The inverse-or-zero of the difference between 33 and Bits. |
LHS | Left-hand side of the operation. Usually corresponds to the processor’s st0. |
LhsInv | The inverse-or-zero of LHS. Needed to check whether LHS is unequal to 0. |
RHS | Right-hand side of the operation. Usually corresponds to the processor’s st1. |
RhsInv | The inverse-or-zero of RHS. Needed to check whether RHS is unequal to 0. |
Result | The result (or intermediate result) of the instruction requested by the processor. |
LookupMultiplicity | The number of times the processor has executed the current instruction with the same arguments. |
An example U32 Table follows. Some columns are omitted for presentation reasons. All cells in the U32 Table contain elements of the B-field. For clearer illustration of the mechanics, the columns marked “” are presented in base 2, whereas columns marked “” are in the usual base 10.
| CopyFlag | CI | Bits | LHS | RHS | Result | Result |
|---|---|---|---|---|---|---|
| 1 | and | 0 | 11000 | 11010 | 11000 | 24 |
| 0 | and | 1 | 1100 | 1101 | 1100 | 12 |
| 0 | and | 2 | 110 | 110 | 110 | 6 |
| 0 | and | 3 | 11 | 11 | 11 | 3 |
| 0 | and | 4 | 1 | 1 | 1 | 1 |
| 0 | and | 5 | 0 | 0 | 0 | 0 |
| 1 | pow | 0 | 10 | 101 | 100000 | 32 |
| 0 | pow | 1 | 10 | 10 | 100 | 4 |
| 0 | pow | 2 | 10 | 1 | 10 | 2 |
| 0 | pow | 3 | 10 | 0 | 1 | 1 |
| 1 | log_2_floor | 0 | 100110 | 0 | 101 | 5 |
| 0 | log_2_floor | 1 | 10011 | 0 | 101 | 5 |
| 0 | log_2_floor | 2 | 1001 | 0 | 101 | 5 |
| 0 | log_2_floor | 3 | 100 | 0 | 101 | 5 |
| 0 | log_2_floor | 4 | 10 | 0 | 101 | 5 |
| 0 | log_2_floor | 5 | 1 | 0 | 101 | 5 |
| 0 | log_2_floor | 6 | 0 | 0 | -1 | -1 |
| 1 | lt | 0 | 11111 | 11011 | 0 | 0 |
| 0 | lt | 1 | 1111 | 1101 | 0 | 0 |
| 0 | lt | 2 | 111 | 110 | 0 | 0 |
| 0 | lt | 3 | 11 | 11 | 10 | 2 |
| 0 | lt | 4 | 1 | 1 | 10 | 2 |
| 0 | lt | 5 | 0 | 0 | 10 | 2 |
The AIR verifies the correct update of each consecutive pair of rows.
For most instructions, the current least significant bit of both LHS and RHS is eliminated between two consecutive rows.
This eliminated bit is used to successively build the required result in the Result column.
For instruction pow, only the least significant bit RHS is eliminated, while LHS remains unchanged throughout the section.
There are 6 instructions the U32 Table is “aware” of: split, lt, and, log_2_floor, pow, and pop_count.
The instruction split uses the U32 Table for range checking only.
Concretely, the U32 Table ensures that the instruction split’s resulting “high bits” and “low bits” each fit in a u32.
Since the processor does not expect any result from instruction split, the Result must be 0 else the Lookup Argument fails.
Similarly, for instructions log_2_floor and pop_count, the processor always sets the RHS to 0.
For instruction xor, the processor requests the computation of the two arguments’ and and converts the result using the following equality:
Credit for this trick goes, to the best of our knowledge, to Daniel Lubarov.
For the remaining u32 instruction div_mod, the processor triggers the creation of two sections in the U32 Table:
- One section to ensure that the remainder
ris smaller than the divisord. The processor requests the result ofltby setting the U32 Table’sCIregister to the opcode oflt. This also guarantees thatranddeach fit in a u32. - One section to ensure that the quotient
qand the numeratorneach fit in a u32. The processor needs no result, only the range checking capabilities, like for instructionsplit. Consequently, the processor sets the U32 Table’sCIregister to the opcode ofsplit.
If the current instruction is lt, the Result can take on the values 0, 1, or 2, where
- 0 means
LHS>=RHSis definitely known in the current row, - 1 means
LHS<RHSis definitely known in the current row, and - 2 means the result is unknown in the current row.
This is only an intermediate result.
It can never occur in the first row of a section, i.e., when
CopyFlagis 1.
A new row with CopyFlag = 1 can only be inserted if
LHSis 0 or the current instruction ispow, andRHSis 0.
It is impossible to create a valid proof of correct execution of Triton VM if Bits is 33 in any row.
Auxiliary Columns
The U32 Table has 1 auxiliary column, U32LookupServerLogDerivative.
It corresponds to the Lookup Argument with the Processor Table, establishing that whenever the processor executes a u32 instruction, the following holds:
- the processor’s requested left-hand side is copied into
LHS, - the processor’s requested right-hand side is copied into
RHS, - the processor’s requested u32 instruction is copied into
CI, and - the result
Resultis copied to the processor.
Padding
Each padding row is the all-zero row with the exception of
CI, which is the opcode ofsplit, andBitsMinus33Inv, which is .
Additionally, if the U32 Table is non-empty before applying padding, the padding row’s columns CI, LHS, LhsInv, and Result are taken from the U32 Table’s last row.
Arithmetic Intermediate Representation
Let all household items (🪥, 🛁, etc.) be challenges, concretely evaluation points, supplied by the verifier. Let all fruit & vegetables (🥝, 🥥, etc.) be challenges, concretely weights to compress rows, supplied by the verifier. Both types of challenges are X-field elements, i.e., elements of .
Initial Constraints
- If the
CopyFlagis 0, thenU32LookupServerLogDerivativeis 0. Otherwise, theU32LookupServerLogDerivativehas accumulated the first row with multiplicityLookupMultiplicityand with respect to challenges 🥜, 🌰, 🥑, and 🥕, and indeterminate 🧷.
Initial Constraints as Polynomials
(CopyFlag - 1)·U32LookupServerLogDerivative
+ CopyFlag·(U32LookupServerLogDerivative·(🧷 - 🥜·LHS - 🌰·RHS - 🥑·CI - 🥕·Result) - LookupMultiplicity)
Consistency Constraints
- The
CopyFlagis 0 or 1. - If
CopyFlagis 1, thenBitsis 0. BitsMinus33Invis the inverse of (Bits- 33).LhsInvis 0 or the inverse ofLHS.Lhsis 0 orLhsInvis the inverse ofLHS.RhsInvis 0 or the inverse ofRHS.Rhsis 0 orRhsInvis the inverse ofRHS.- If
CopyFlagis 0 and the current instruction isltandLHSis 0 andRHSis 0, thenResultis 2. - If
CopyFlagis 1 and the current instruction isltandLHSis 0 andRHSis 0, thenResultis 0. - If the current instruction is
andandLHSis 0 andRHSis 0, thenResultis 0. - If the current instruction is
powandRHSis 0, thenResultis 1. - If
CopyFlagis 0 and the current instruction islog_2_floorandLHSis 0, thenResultis -1. - If
CopyFlagis 1 and the current instruction islog_2_floorandLHSis 0, the VM crashes. - If
CopyFlagis 0 and the current instruction ispop_countandLHSis 0, thenResultis 0. - If
CopyFlagis 0, thenLookupMultiplicityis 0.
Written in Disjunctive Normal Form, the same constraints can be expressed as:
- The
CopyFlagis 0 or 1. CopyFlagis 0 orBitsis 0.BitsMinus33Invthe inverse of (Bits- 33).LhsInvis 0 or the inverse ofLHS.Lhsis 0 orLhsInvis the inverse ofLHS.RhsInvis 0 or the inverse ofRHS.Rhsis 0 orRhsInvis the inverse ofRHS.CopyFlagis 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countorLHSis not 0 orRHSis not 0 orResultis 2.CopyFlagis 0 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countorLHSis not 0 orRHSis not 0 orResultis 0.CIis the opcode ofsplit,lt,pow,log_2_floor, orpop_countorLHSis not 0 orRHSis not 0 orResultis 0.CIis the opcode ofsplit,lt,and,log_2_floor, orpop_countorRHSis not 0 orResultis 1.CopyFlagis 1 orCIis the opcode ofsplit,lt,and,pow, orpop_countorLHSis not 0 orResultis -1.CopyFlagis 0 orCIis the opcode ofsplit,lt,and,pow, orpop_countorLHSis not 0.CopyFlagis 1 orCIis the opcode ofsplit,lt,and,pow, orlog_2_floororLHSis not 0 orResultis 0.CopyFlagis 1 orLookupMultiplicityis 0.
Consistency Constraints as Polynomials
CopyFlag·(CopyFlag - 1)CopyFlag·Bits1 - BitsMinus33Inv·(Bits - 33)LhsInv·(1 - LHS·LhsInv)LHS·(1 - LHS·LhsInv)RhsInv·(1 - RHS·RhsInv)RHS·(1 - RHS·RhsInv)(CopyFlag - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(1 - LHS·LhsInv)·(1 - RHS·RhsInv)·(Result - 2)(CopyFlag - 0)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(1 - LHS·LhsInv)·(1 - RHS·RhsInv)·(Result - 0)(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(1 - LHS·LhsInv)·(1 - RHS·RhsInv)·Result(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(1 - RHS·RhsInv)·(Result - 1)(CopyFlag - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(pop_count))·(1 - LHS·LhsInv)·(Result + 1)CopyFlag·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(pop_count))·(1 - LHS·LhsInv)(CopyFlag - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(1 - LHS·LhsInv)·(Result - 0)(CopyFlag - 1)·LookupMultiplicity
Transition Constraints
Even though they are never explicitly represented, it is useful to alias the LHS’s and RHS’s least significant bit, or “lsb.”
Given two consecutive rows, the (current) least significant bit of LHS can be computed by subtracting twice the next row’s LHS from the current row’s LHS.
These aliases, i.e., LhsLsb := LHS - 2·LHS' and RhsLsb := RHS - 2·RHS', are used throughout the following.
- If the
CopyFlagin the next row is 1 and the current instruction is notpow, thenLHSin the current row is 0. - If the
CopyFlagin the next row is 1, thenRHSin the current row is 0. - If the
CopyFlagin the next row is 0, thenCIin the next row isCIin the current row. - If the
CopyFlagin the next row is 0 andLHSin the current row is unequal to 0 and the current instruction is notpow, thenBitsin the next row isBitsin the current row plus 1. - If the
CopyFlagin the next row is 0 andRHSin the current row is unequal to 0, thenBitsin the next row isBitsin the current row plus 1. - If the
CopyFlagin the next row is 0 and the current instruction is notpow, thenLhsLsbis either 0 or 1. - If the
CopyFlagin the next row is 0, thenRhsLsbis either 0 or 1. - If the
CopyFlagin the next row is 0 and the current instruction isltandResultin the next row is 0, thenResultin the current row is 0. - If the
CopyFlagin the next row is 0 and the current instruction isltandResultin the next row is 1, thenResultin the current row is 1. - If the
CopyFlagin the next row is 0 and the current instruction isltandResultin the next row is 2 andLhsLsbis 0 andRhsLsbis 1, thenResultin the current row is 1. - If the
CopyFlagin the next row is 0 and the current instruction isltandResultin the next row is 2 andLhsLsbis 1 andRhsLsbis 0, thenResultin the current row is 0. - If the
CopyFlagin the next row is 0 and the current instruction isltandResultin the next row is 2 andLhsLsbisRhsLsband theCopyFlagin the current row is 0, thenResultin the current row is 2. - If the
CopyFlagin the next row is 0 and the current instruction isltandResultin the next row is 2 andLhsLsbisRhsLsband theCopyFlagin the current row is 1, thenResultin the current row is 0. - If the
CopyFlagin the next row is 0 and the current instruction isand, thenResultin the current row is twiceResultin the next row plus the product ofLhsLsbandRhsLsb. - If the
CopyFlagin the next row is 0 and the current instruction islog_2_floorandLHSin the next row is 0 andLHSin the current row is not 0, thenResultin the current row isBits. - If the
CopyFlagin the next row is 0 and the current instruction islog_2_floorandLHSin the next row is not 0, thenResultin the current row isResultin the next row. - If the
CopyFlagin the next row is 0 and the current instruction ispow, thenLHSremains unchanged. - If the
CopyFlagin the next row is 0 and the current instruction ispowandRhsLsbin the current row is 0, thenResultin the current row isResultin the next row squared. - If the
CopyFlagin the next row is 0 and the current instruction ispowandRhsLsbin the current row is 1, thenResultin the current row isResultin the next row squared timesLHSin the current row. - If the
CopyFlagin the next row is 0 and the current instruction ispop_count, thenResultin the current row isResultin the next row plusLhsLsb. - If the
CopyFlagin the next row is 0, thenU32LookupServerLogDerivativein the next row isU32LookupServerLogDerivativein the current row. - If the
CopyFlagin the next row is 1, thenU32LookupServerLogDerivativein the next row has accumulated the next row with multiplicityLookupMultiplicityand with respect to challenges 🥜, 🌰, 🥑, and 🥕, and indeterminate 🧷.
Written in Disjunctive Normal Form, the same constraints can be expressed as:
CopyFlag’ is 0 orLHSis 0 orCIis the opcode ofpow.CopyFlag’ is 0 orRHSis 0.CopyFlag’ is 1 orCI’ isCI.CopyFlag’ is 1 orLHSis 0 orCIis the opcode ofpoworBits’ isBits+ 1.CopyFlag’ is 1 orRHSis 0 orBits’ isBits+ 1.CopyFlag’ is 1 orCIis the opcode ofpoworLhsLsbis 0 orLhsLsbis 1.CopyFlag’ is 1 orRhsLsbis 0 orRhsLsbis 1.CopyFlag’ is 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countor (Result’ is 1 or 2) orResultis 0.CopyFlag’ is 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countor (Result’ is 0 or 2) orResultis 1.CopyFlag’ is 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countor (Result’ is 0 or 1) orLhsLsbis 1 orRhsLsbis 0 orResultis 1.CopyFlag’ is 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countor (Result’ is 0 or 1) orLhsLsbis 0 orRhsLsbis 1 orResultis 0.CopyFlag’ is 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countor (Result’ is 0 or 1) orLhsLsbis unequal toRhsLsborCopyFlagis 1 orResultis 2.CopyFlag’ is 1 orCIis the opcode ofsplit,and,pow,log_2_floor, orpop_countor (Result’ is 0 or 1) orLhsLsbis unequal toRhsLsborCopyFlagis 0 orResultis 0.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,pow,log_2_floor, orpop_countorResultis twiceResult’ plus the product ofLhsLsbandRhsLsb.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,and,pow, orpop_countorLHS’ is not 0 orLHSis 0 orResultisBits.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,and,pow, orpop_countorLHS’ is 0 orResultisResult’.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,and,log_2_floor, orpop_countorLHS’ isLHS.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,and,log_2_floor, orpop_countorRhsLsbis 1 orResultisResult’ timesResult’.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,and,log_2_floor, orpop_countorRhsLsbis 0 orResultisResult’ timesResult’ timesLHS.CopyFlag’ is 1 orCIis the opcode ofsplit,lt,and,pow, orlog_2_floororResultisResult’ plusLhsLsb.CopyFlag’ is 1 orU32LookupServerLogDerivative’ isU32LookupServerLogDerivative.CopyFlag’ is 0 or the difference ofU32LookupServerLogDerivative’ andU32LookupServerLogDerivativetimes(🧷 - 🥜·LHS' - 🌰·RHS' - 🥑·CI' - 🥕·Result')isLookupMultiplicity’.
Transition Constraints as Polynomials
(CopyFlag' - 0)·LHS·(CI - opcode(pow))(CopyFlag' - 0)·RHS(CopyFlag' - 1)·(CI' - CI)(CopyFlag' - 1)·LHS·(CI - opcode(pow))·(Bits' - Bits - 1)(CopyFlag' - 1)·RHS·(Bits' - Bits - 1)(CopyFlag' - 1)·(CI - opcode(pow))·LhsLsb·(LhsLsb - 1)(CopyFlag' - 1)·RhsLsb·(RhsLsb - 1)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result' - 1)·(Result' - 2)·(Result - 0)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result' - 0)·(Result' - 2)·(Result - 1)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result' - 0)·(Result' - 1)·(LhsLsb - 1)·(RhsLsb - 0)·(Result - 1)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result' - 0)·(Result' - 1)·(LhsLsb - 0)·(RhsLsb - 1)·(Result - 0)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result' - 0)·(Result' - 1)·(1 - LhsLsb - RhsLsb + 2·LhsLsb·RhsLsb)·(CopyFlag - 1)·(Result - 2)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result' - 0)·(Result' - 1)·(1 - LhsLsb - RhsLsb + 2·LhsLsb·RhsLsb)·(CopyFlag - 0)·(Result - 0)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(Result - 2·Result' - LhsLsb·RhsLsb)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(pop_count))·(1 - LHS'·LhsInv')·LHS·(Result - Bits)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(pop_count))·LHS'·(Result' - Result)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(LHS' - LHS)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(RhsLsb - 1)·(Result - Result'·Result')(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(log_2_floor))·(CI - opcode(pop_count))·(RhsLsb - 0)·(Result - Result'·Result'·LHS)(CopyFlag' - 1)·(CI - opcode(split))·(CI - opcode(lt))·(CI - opcode(and))·(CI - opcode(pow))·(CI - opcode(log_2_floor))·(Result - Result' - LhsLsb)(CopyFlag' - 1)·(U32LookupServerLogDerivative' - U32LookupServerLogDerivative)(CopyFlag' - 0)·((U32LookupServerLogDerivative' - U32LookupServerLogDerivative)·(🧷 - 🥜·LHS - 🌰·RHS - 🥑·CI - 🥕·Result) - LookupMultiplicity')
Terminal Constraints
LHSis 0 or the current instruction ispow.RHSis 0.
Terminal Constraints as Polynomials
LHS·(CI - opcode(pow))RHS
Table Linking
Triton VM’s tables are linked together using a variety of different cryptographic arguments. The section on arithmetization incorporates all the necessary ingredients by defining the corresponding parts of the Arithmetic Execution Tables and the Arithmetic Intermediate Representation. However, that presentation doesn’t make it easy to follow and understand the specific arguments in use. Therefor, the distinct “cross-table” or “table-linking” arguments are presented here in isolation.
Compressing Multiple Elements
Mathematically, all arguments used in Triton VM are about single elements of the finite field . In practice, it is very useful to argue about multiple elements. A common trick is to “compress” multiple elements into a single one using random weights. These weights are “supplied by the STARK verifier,” i.e., sampled using the Fiat-Shamir heuristic after the prover has committed to the elements in question. For example, if , , and are to be incorporated into the cryptographic argument, then the prover
- commits to , , and ,
- samples weights , , and using the Fiat-Shamir heuristic,
- “compresses” the elements in question to , and
- uses in the cryptographic argument.
In the following, all cryptographic arguments are presented using single field elements. Depending on the use case, this single element represents multiple, “compressed” elements.
Permutation Argument
The Permutation Argument establishes that two lists and are permutations of each other. To achieve this, the lists’ elements are interpreted as the roots of polynomials and , respectively:
The two lists and are a permutation of each other if and only if the two polynomials and are identical. By the Schwartz–Zippel lemma, probing the polynomials in a single point establishes the polynomial identity with high probability.1
In Triton VM, the Permutation Argument is generally applied to show that the rows of one table appear in some other table without enforcing the rows’ order in relation to each other. To establish this, the prover
- commits to the main column in question,2
- samples a random challenge through the Fiat-Shamir heuristic,
- computes the running product of and in the respective tables’ auxiliary column.
For example, in Table A:
| main column A | auxiliary column A: running product |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 |
And in Table B:
| main column B | auxiliary column B: running product |
|---|---|
| 2 | |
| 1 | |
| 3 | |
| 0 |
It is possible to establish a subset relation by skipping over certain elements when computing the running product. The running product must incorporate the same elements in both tables. Otherwise, the Permutation Argument will fail.
An example of a subset Permutation Argument can be found between the U32 Table and the Processor Table.
-
This depends on the length of the lists and as well as the field size. For Triton VM, . The polynomials and are evaluated over the auxiliary field with elements. The false positive rate is therefore . ↩
-
See “Compressing Multiple Elements.” ↩
Evaluation Argument
The Evaluation Argument establishes that two lists and are identical. To achieve this, the lists’ elements are interpreted as the coefficients of polynomials and , respectively:
The two lists and are identical if and only if the two polynomials and are identical. By the Schwartz–Zippel lemma, probing the polynomials in a single point establishes the polynomial identity with high probability.1
In Triton VM, the Evaluation Argument is generally used to show that (parts of) some row appear in two tables in the same order. To establish this, the prover
- commits to the main column in question,2
- samples a random challenge through the Fiat-Shamir heuristic,
- computes the running evaluation of and in the respective tables’ auxiliary column.
For example, in both Table A and B:
| main column | auxiliary column: running evaluation |
|---|---|
| 0 | |
| 1 | |
| 2 | |
| 3 |
It is possible to establish a subset relation by skipping over certain elements when computing the running evaluation. The running evaluation must incorporate the same elements in both tables. Otherwise, the Evaluation Argument will fail.
Examples for subset Evaluation Arguments can be found between the Hash Table and the Processor Table.
-
This depends on the length of the lists and as well as the field size. For Triton VM, . The polynomials and are evaluated over the auxiliary field with elements. The false positive rate is therefore . ↩
-
See “Compressing Multiple Elements.” ↩
Lookup Argument
The Lookup Argument establishes that all elements of list also occur in list . In this context, contains the values that are being looked up, while is the lookup table.1 Both lists and may contain duplicates. However, it is inefficient if does, and is therefore assumed not to.
The example at the end of this section summarizes the necessary computations for the Lookup Argument. The rest of the section derives those computations. The first step is to interpret both lists’ elements as the roots of polynomials and , respectively:
By counting the number of occurrences of unique elements and eliminating duplicates, can equivalently be expressed as:
The next step uses
- the formal derivative of , and
- the multiplicity-weighted formal derivative of .
The former is the familiar formal derivative:
The multiplicity-weighted formal derivative uses the lookup-multiplicities as additional factors:
Let the greatest common divisor of and . The polynomial has the same roots as , but all roots have multiplicity 1. This polynomial is identical to if and only if all elements in list also occur in list .
A similar property holds for the formal derivatives: The polynomial is identical to if and only if all elements in list also occur in list . By solving for and equating, the following holds:
Optimization through Logarithmic Derivatives
The logarithmic derivative of is defined as . Furthermore, the equality of monic polynomials and is equivalent to the equality of their logarithmic derivatives.2 This allows rewriting above equation as:
Using logarithmic derivatives for the equality check decreases the computational effort for both prover and verifier. Concretely, instead of four running products – one each for , , , and – only two logarithmic derivatives are needed. Namely, considering once again list containing duplicates, above equation can be written as:
To compute the sums, the lists and are main columns in the two respective tables. Additionally, the lookup multiplicity is recorded explicitly in a main column of the lookup table.
Example
In Table A:
| main column A | auxiliary column A: logarithmic derivative |
|---|---|
| 0 | |
| 2 | |
| 2 | |
| 1 | |
| 2 |
And in Table B:
| main column B | multiplicity | auxiliary column B: logarithmic derivative |
|---|---|---|
| 0 | 1 | |
| 1 | 1 | |
| 2 | 3 |
It is possible to establish a subset relation by skipping over certain elements when computing the logarithmic derivative. The logarithmic derivative must incorporate the same elements with the same multiplicity in both tables. Otherwise, the Lookup Argument will fail.
An example for a Lookup Argument can be found between the Program Table and the Processor Table.
-
The lookup table may represent a mapping from one or more “input” elements to one or more “output” elements – see “Compressing Multiple Elements.” ↩
-
See Lemma 3 in this paper for a proof. ↩
Memory Consistency
Triton has three memory-like units: the RAM, the jump stack, and the op stack. Each such unit has a corresponding table. Memory-consistency is the property that whenever the processor reads a data element from these units, the value that it receives corresponds to the value sent the last time when that cell was written. Memory consistency follows from two intermediate properties.
- Contiguity of regions of constant memory pointer. After selecting from each table all the rows with any given memory pointer, the resulting sublist is contiguous, which is to say, there are no gaps and two such sublists can never interleave.
- Inner-sorting within contiguous regions. Within each such contiguous region, the rows are sorted in ascending order by clock cycle.
The contiguity of regions of constant memory pointer is established differently for the RAM Table than for the Op Stack or Jump Stack Tables. The Op Stack and Jump Stack Tables enjoy a particular property whereby the memory pointer can only ever increase or decrease by one (or stay the same). As a result, simple AIR constraints can enforce the correct sorting by memory pointer. In contrast, the memory pointer for the RAM Table can jump arbitrarily. As explained in the next section, a Contiguity Argument establishes contiguity.
The correct inner sorting is established the same way for all three memory-like tables. Their respective clock jump differences – differences of clock cycles within regions of constant memory pointer – are shown to be contained in the set of all clock cycles through Lookup Arguments. Under reasonable assumptions about the running time, this fact implies that all clock jumps are directed forwards, as opposed to backwards, which in turn implies that the rows are sorted for clock cycle.
The next sections elaborate on these constructions. A dedicated section shows that these two properties do indeed suffice to prove memory consistency.
Contiguity of Memory-Pointer Regions
Contiguity for Op Stack Table
In each cycle, the memory pointer for the Op Stack Table, op_stack_pointer, can only ever increase by one, remain the same, or decrease by one.
As a result, it is easy to enforce that the entire table is sorted for memory pointer using one initial constraint and one transition constraint.
- Initial constraint:
op_stack_pointerstarts with 161, so in terms of polynomials the constraint isop_stack_pointer - 16. - Transition constraint: the new
op_stack_pointeris either the same as the previous or one larger. The polynomial representation for this constraint is(op_stack_pointer' - op_stack_pointer - 1) · (op_stack_pointer' - op_stack_pointer).
Contiguity for Jump Stack Table
Analogously to the Op Stack Table, the Jump Stack’s memory pointer jsp can only ever decrease by one, remain the same, or increase by one, within each cycle. As a result, similar constraints establish that the entire table is sorted for memory pointer.
- Initial constraint:
jspstarts with zero, so in terms of polynomials the constraint isjsp. - Transition constraint: the new
jspis either the same as the previous or one larger. The polynomial representation for this constraint is(jsp' - jsp - 1) * (jsp' - jsp).
Contiguity for RAM Table
The Contiguity Argument for the RAM table establishes that all RAM pointer regions start with distinct values. It is easy to ignore consecutive duplicates in the list of all RAM pointers using one additional main column. This allows identification of the RAM pointer values at the regions’ boundaries, . The Contiguity Argument then shows that the list contains no duplicates. For this, it uses Bézout’s identity for univariate polynomials. Concretely, the prover shows that for the polynomial with all elements of as roots, i.e., and its formal derivative , there exist and with appropriate degrees such that In other words, the Contiguity Argument establishes that the greatest common divisor of and is 1. This implies that all roots of have multiplicity 1, which holds if and only if there are no duplicate elements in list .
The following columns and constraints are needed for the Contiguity Argument:
- Main column
iordand two deterministic transition constraints enable conditioning on a changed memory pointer. - Main columns
bcpc0andbcpc1and two deterministic transition constraints contain and constrain the symbolic Bézout coefficient polynomials’ coefficients. - Auxiliary column
rppis a running product similar to that of a conditioned permutation argument. A randomized transition constraint verifies the correct accumulation of factors for updating this column. - Auxiliary column
fdis the formal derivative ofrpp. A randomized transition constraint verifies the correct application of the product rule of differentiation to update this column. - Auxiliary columns
bc0andbc1build up the Bézout coefficient polynomials based on the corresponding main columns,bcpc0andbcpc1. Two randomized transition constraints enforce the correct build-up of the Bézout coefficient polynomials. - A terminal constraint takes the weighted sum of the running product and the formal derivative, where the weights are the Bézout coefficient polynomials, and equates it to one. This equation asserts the Bézout relation.
The following table illustrates the idea. Columns not needed for establishing memory consistency are not displayed.
ramp | iord | bcpc0 | bcpc1 | rpp | fd | bc0 | bc1 |
|---|---|---|---|---|---|---|---|
| 0 | |||||||
| 0 | |||||||
| 0 | |||||||
| 0 | |||||||
| - |
The values contained in the auxiliary columns are undetermined until the verifier’s challenge is known; before that happens it is worthwhile to present the polynomial expressions in , anticipating the substitution . The constraints are articulated relative to α.
The inverse of RAMP difference iord takes the inverse of the difference between the current and next ramp values if that difference is non-zero, and zero else. This constraint corresponds to two transition constraint polynomials:
(ramp' - ramp) ⋅ ((ramp' - ramp) ⋅ iord - 1)iord ⋅ (ramp' - ramp) ⋅ iord - 1)
The running product rpp starts with initially, which is enforced by an initial constraint.
It accumulates a factor in every pair of rows where ramp ≠ ramp'. This evolution corresponds to one transition constraint: (ramp' - ramp) ⋅ (rpp' - rpp ⋅ (α - ramp')) + (1 - (ramp' - ramp) ⋅ di) ⋅ (rpp' - rp)
Denote by the polynomial that accumulates all factors in every pair of rows where .
The column fd contains the “formal derivative” of the running product with respect to .
The formal derivative is initially , which is enforced by an initial constraint.
The transition constraint applies the product rule of differentiation conditioned upon the difference in ramp being nonzero; in other words, if then the same value persists; but if then is mapped as
This update rule is called the product rule of differentiation because, assuming , then
The transition constraint for fd is (ramp' - ramp) ⋅ (fd' - rp - (α - ramp') ⋅ fd) + (1 - (ramp' - ramp) ⋅ iord) ⋅ (fd' - fd).
The polynomials and are the Bézout coefficient polynomials satisfying the relation The prover finds and as the minimal-degree Bézout coefficients as returned by the extended Euclidean algorithm. Concretely, the degree of is smaller than the degree of , and the degree of is smaller than the degree of .
The (scalar) coefficients of the Bézout coefficient polynomials are recorded in main columns bcpc0 and bcpc1, respectively.
The transition constraints for these columns enforce that the value in one such column can only change if the memory pointer ramp changes.
However, unlike the conditional update rule enforced by the transition constraints of rp and fd, the new value is unconstrained.
Concretely, the two transition constraints are:
(1 - (ramp' - ramp) ⋅ iord) ⋅ (bcpc0' - bcpc0)(1 - (ramp' - ramp) ⋅ iord) ⋅ (bcpc1' - bcpc1)
Additionally, bcpc0 must initially be zero, which is enforced by an initial constraint.
This upper-bounds the degrees of the Bézout coefficient polynomials, which are built from main columns bcpc0 and bcpc1.
Two transition constraints enforce the correct build-up of the Bézout coefficient polynomials:
(1 - (ramp' - ramp) ⋅ iord) ⋅ (bc0' - bc0) + (ramp' - ramp) ⋅ (bc0' - α ⋅ bc0 - bcpc0')(1 - (ramp' - ramp) ⋅ iord) ⋅ (bc1' - bc1) + (ramp' - ramp) ⋅ (bc1' - α ⋅ bc1 - bcpc1')
Additionally, bc0 must initially be zero, and bc1 must initially equal bcpc1.
This is enforced by initial constraints bc0 and bc1 - bcpc1.
Lastly, the verifier verifies the randomized AIR terminal constraint bc0 ⋅ rpp + bc1 ⋅ fd - 1.
Completeness.
For honest provers, the gcd is guaranteed to be one. As a result, the protocol has perfect completeness.
Soundness.
If the table has at least one non-contiguous region, then and share at least one factor. As a result, no Bézout coefficients and can exist such that . The verifier therefore probes unequal polynomials of degree at most , where is the length of the execution trace, which is upper bounded by . According to the Schwartz-Zippel lemma, the false positive probability is at most .
Zero-Knowledge.
Since the contiguity argument is constructed using only AET and AIR, zero-knowledge follows from Triton VM’s zk-STNARK engine.
Summary of constraints
We present a summary of all constraints.
Initial
bcpc0bc0bc1 - bcpc1fd - 1rpp - (α - ramp)
Consistency
None.
Transition
(ramp' - ramp) ⋅ ((ramp' - ramp) ⋅ iord - 1)iord ⋅ ((ramp' - ramp) ⋅ iord - 1)(1 - (ramp' - ramp) ⋅ iord) ⋅ (bcpc0' - bcpc0)(1 - (ramp' - ramp) ⋅ iord) ⋅ (bcpc1' - bcpc1)(ramp' - ramp) ⋅ (rpp' - rpp ⋅ (α - ramp')) + (1 - (ramp' - ramp) ⋅ iord) ⋅ (rpp' - rpp)(ramp' - ramp) ⋅ (fd' - rp - (α - ramp') ⋅ fd) + (1 - (ramp' - ramp) ⋅ iord) ⋅ (fd' - fd)(1 - (ramp' - ramp) ⋅ iord) ⋅ (bc0' - bc0) + (ramp' - ramp) ⋅ (bc0' - α ⋅ bc0 - bcpc0')(1 - (ramp' - ramp) ⋅ iord) ⋅ (bc1' - bc1) + (ramp' - ramp) ⋅ (bc1' - α ⋅ bc1 - bcpc1')
Terminal
bc0 ⋅ rpp + bc1 ⋅ fd - 1
-
See data structures and registers for explanations of the specific value 16. ↩
Clock Jump Differences and Inner Sorting
The previous sections show how it is proven that in the Jump Stack, Op Stack, and RAM Tables, the regions of constant memory pointer are contiguous. The next step is to prove that within each contiguous region of constant memory pointer, the rows are sorted for clock cycle. That is the topic of this section.
The problem arises from clock jumps, which describes the phenomenon when the clock cycle increases even though the memory pointer does not change. If arbitrary jumps were allowed, nothing would prevent the cheating prover from using a table where higher rows correspond to later states, giving rise to an exploitable attack. So it must be shown that every clock jump is directed forward and not backward.
Our strategy is to show that the difference, i.e., the next clock cycle minus the current clock cycle, is itself a clock cycle. Recall that the Processor Table’s clock cycles run from 0 to . Therefore, a forward directed clock jump difference is in , whereas a backward directed clock jump’s difference is in . No other clock jump difference can occur. If , there is no overlap between sets and . As a result, in this regime, showing that a clock jump difference is in guarantees that the jump is forward-directed.
The set of values in the Processor Table’s clock cycle column is .
A standard Lookup Argument can show that the clock jump differences are elements of that column.
Since all three memory-like tables look up the same property, the Processor Table acts as a single server as opposed to three distinct servers.
Concretely, the lookup multiplicities of the three clients, i.e., the memory-like tables, are recorded in a single column cjd_mul.
It contains the element-wise sum of the three distinct lookup multiplicities.
Proof of Memory Consistency
Whenever the Processor Table reads a value “from” a memory-like table, this value appears nondeterministically and is unconstrained by the main table AIR constraints. However, there is a permutation argument that links the Processor Table to the memory-like table in question. The construction satisfies memory consistency if it guarantees that whenever a memory cell is read, its value is consistent with the last time that cell was written.
The above is too informal to provide a meaningful proof for. Let’s put formal meanings on the proposition and premises, before reducing the former to the latter.
Let denote the Processor Table and denote the memory-like table. Both have height . Both have columns clk, mp, and val. For the column clk coincides with the index of the row. has another column ci, which contains the current instruction, which is write, read, or any. Obviously, mp and val are abstract names that depend on the particular memory-like table, just like write, read, and any are abstract instructions that depend on the type of memory being accessed. In the following math notation we use to denote the column name and to denote the value that the column might take in a given row.
Definition 1 (contiguity): The memory-like table is contiguous iff all sublists of rows with the same memory pointer mp are contiguous. Specifically, for any given memory pointer , there are no rows with a different memory pointer in between rows with memory pointer .
Definition 2 (regional sorting): The memory-like table is regionally sorted iff for every contiguous region of constant memory pointer, the clock cycle increases monotonically.
The symbol denotes the integer less than operator, after lifting the operands from the finite field to the integers.
Definition 3 (memory consistency): A Processor Table has memory consistency if whenever a memory cell at location is read, its value corresponds to the previous time the memory cell at location was written. Specifically, there are no writes in between the write and the read, that give the cell a different value.
Theorem 1 (memory consistency): Let be a Processor Table. If there exists a memory-like table such that
- selecting for the columns
clk,mp,val, the two tables’ lists of rows are permutations of each other; and - is contiguous and regionally sorted; and
- has no changes in
valthat coincide with clock jumps;
then has memory consistency.
Proof. For every memory pointer value , select the sublist of rows in order. The way this sublist is constructed guarantees that it coincides with the contiguous region of where the memory pointer is also .
Iteratively apply the following procedure to : remove the bottom-most row if it does not correspond to a row that constitutes a counter-example to memory consistency. Specifically, let be the clock cycle of the previous row in .
- If satisfies then by construction it also satisfies . As a result, row is not part of a counter-example to memory consistency. We can therefore remove the bottom-most row and proceed to the next iteration of the outermost loop.
- If then we can safely ignore this row: if there is no clock jump, then the absence of a -instruction guarantees that cannot change; and if there is a clock jump, then by assumption on , cannot change. So set to the clock cycle of the row above it in and proceed to the next iteration of the inner loop. If there are no rows left for to index, then there is no possible counterexample for and so remove the bottom-most row of and proceed to the next iteration of the outermost loop.
- The case cannot occur because by construction of , cannot change.
- The case cannot occur because the list was constructed by selecting only elements with the same memory pointer.
- This list exhausts the possibilities of condition (1).
When consists of only two rows, it can contain no counter-examples. By applying the above procedure, we can reduce every correctly constructed sublist to a list consisting of two rows. Therefore, for every , the sublist is free of counter-examples to memory consistency. Equivalently, is memory consistent.
Program Attestation
“Program attestation” is the notion of cryptographically linking a program to the proof produced by that program’s execution. Informally, program attestation allows Triton VM to prove claims of the form:
There exists a program with hash digest X that, given input Y, produces output Z.
Without program attestation, Triton VM would only be able to prove claims of the form:
There exists a program that, given input Y, produces output Z.
The proof system is zero-knowledge with respect to the actual program. That is, the verifier learns nothing about the program of which correct execution is proven, except the program’s digest1. This property is generally desirable, for example to keep a specific machine learning model secret while being able to prove its correct execution. However, it can be equally desirable to reveal the program, for example to allow code auditing. In such cases, the program’s source code can be revealed and digest equality can be checked.
As is the case throughout Triton VM, the used hash function is Tip5.
Mechanics
Program attestation is part of initializing Triton VM. That is, control is passed to the to-be-executed program only after the following steps have been performed:
- The instructions, located in program memory, are padded. The padding follows Tip5’s rules for input of variable length2.
- The padded instructions are copied to the Hash Table.
- The Hash Table computes the program’s digest by iterating Tip5 multiple times in Sponge mode.
- The program digest is copied to the bottom of the operational stack, i.e., stack elements
st11throughst15.
The program digest is part of the (public) claim. During proof verification, AIR constraints in the Hash Table establish that the claimed and the computed program digests are identical, and that the digest was computed integrally. This establishes verifiable integrity of the publicly claimed program digest. Below figure visualizes the interplay of tables and public data for proof verification.
Notably, a program has access to the hash digest of itself. This is useful for recursive verification: since the program digest is both part of the proof that is being verified and accessible during execution, the two can be checked for equality at runtime. This way, the recursive verifier can know whether it is actually recursing, or whether it is verifying a proof for some other program. After all, the hash digest of the verifier program cannot be hardcoded into the verifier program, because that would be a circular dependency.
-
Since hash functions are deterministic, a programmer desiring resistance against enumeration attacks might want to include blinding elements This is easily possible in, for example, dead code, by including instructions like
push random_element. The distributionrandom_elementis sampled from and the number of such instructions determine the security level against enumeration attacks. ↩ -
Padding is one 1 followed by the minimal number of 0’s necessary to make the padded input length a multiple of the , which is 10. See also section 2.5 “Fixed-Length versus Variable-Length” in the Tip5 paper. ↩
Zero-Knowledge
Formally, a proof system is zero-knowledge if there is an efficient simulator capable of producing transcripts without knowledge of a secret witness and even when no witness exists, such that no efficient distinguisher can distinguish simulated transcripts from authentic ones. This page describes the steps the Triton VM prover undertakes to ensure that the proofs it produces satisfy this property, and furthermore proves that these techniques do in fact realize that intention.
Zero-Knowledge of the Interactive Oracle Proofs
Triton VM applies three randomization steps, summarized as follows.
- A uniformly random polynomial, called the batch randomizer, is added to the batch of polynomials. With the addition of the batch randomizer, any linear combination of the trace and quotient polynomials is itself uniform and therefore perfectly independent of the witness. All codewords that arise in the course of the low-degree test are downstream from this linear combination and therefore share this property.
- All trace polynomials (both main and auxiliary) contain field elements worth of entropy. The variable is chosen such that all in-domain and out-of-domain rows that are queried as part of the batch-check of the low-degree test are uniform.
- The quotient table is extended with one column and the entire table is randomized in a way that preserves the ability to extract the value of the quotient at a certain out-of-domain point while perfectly hiding the values of the individual segments for each revealed row.
Batch-Randomizer
The batch randomizer is a uniformly random polynomial that is included into the random linear combination of polynomials in the batching step, in preparation for the low-degree test (or, depending on your perspective, as its initialization step). Its codeword (specifically, its list of evaluations on the trace domain) is adjoined to the auxiliary trace but left unconstrained by all AIR constraints.
The effect of adding the batch randomizer is that all codewords sent in the course of the low-degree test are perfectly independent of the witness. To see this, let be the first combination codeword in a given accepting transcript, and let be any choice for the randomized trace polynomials and any choice for the randomized quotient segment polynomials. Isolate the batch-randomizer term in the batch equation
where is the LDT domain and the sums run over all randomized trace polynomials and all randomized quotient segment polynomials. The right hand side, , must be a Reed-Solomon codeword because it is a linear combination of Reed-Solomon codewords. Consequently, there must be some low degree polynomial that agrees with on . The distribution of equals that of up to translation, and even this “up to translation” is unnecessary because the distribution is in fact uniform over polynomials of bounded degree. This argument establishes that is a uniformly random Reed-Solomon codeword and, consequently, that no distinguisher has any advantage over a random guess at distinguishing simulated from authentic transcripts based on the codewords from the low-degree test alone because that would entail distinguishing distributions that are identical.
Randomized Trace Polynomials
Let be the main trace polynomials (defined over base field ) and the auxiliary trace polynomials (defined over extension field with extension degree ). To randomize these polynomials we compute
where each is a uniformly random polynomial over the respective field of degree less than , and where is the zerofier (vanishing polynomial) for the trace domain.
The addition of -many randomizer coefficients ensures that values of are independent of , provided that is drawn from the same field and does not live in the trace domain. To see this, let be distinct indeterminates satisfying these criteria. Restricting the above equation to gives points that must agree with, and may be found through interpolation. This method for obtaining works for any trace polynomial .
Since the target domain of the low-degree extension step, also known as the LDT domain, is a disjoint set from the trace domain, it follows that rows of the low-degree extended trace are independent of the trace. Let be the number of in-domain rows queried by the low-degree test. Obviously, must be true for independence, but this alone is not enough because there are also out-of-domain rows released in the course of the DEEP-ALI protocol. For these rows we must take into account the extension degree as well as the fan-in of the AIR circuit. Since the out-of-domain indeterminate lives in the extension field, one out-of-domain row of the main table is equivalent to base field rows. Furthermore, to admit one evaluation of the AIR, rows must be supplied. So for the main trace, the prover discloses an equivalent of and for the auxiliary trace an equivalent of rows. Consequently, for the main trace polynomials and for the auxiliary trace polynomials.
For simplicity, we choose to have only one that works for both main and auxiliary traces. Furthermore, we anticipate the need for a margin of coefficients originating from the randomized quotient table, and 1 coefficient for the Merkle trees. So: .
Note: The batch-randomizer is also trace-randomized: , where is the unrandomized batch-randomizer of uniform coefficients, is the length of the trace domain, and is the trace randomizer for the batch-randomizer which adds another uniform coefficients.
Note: Besides requiring that the LDT and trace domains are disjoint sets, it is also important to disallow verifiers who sample from the trace domain. In the non-interactive case, the probability of this event is negligible and may safely be ignored, but interactively the prover must guard against malicious verifiers employing this strategy.
Quotient Table Randomization
Segmentation is the process of splitting the large quotient polynomial into segments of degree less than such that
Note that is the rate of the Reed-Solomon code and its domain of definition. Moreover, note that (where is the trace length) because of trace polynomial randomization.
To use a randomized quotient table instead of these raw segments, construct segments as follows:
- Sample uniformly of degree less than .
- For , define .
The constant is a fixed parameter of the STARK with the following constraints:
- has multiplicative order larger than , and
- none of the powers are an element of the field’s 2-adic subgroups.
The reasons for this is expanded upon below.
Furthermore, define
and observe that
The “randomized quotient table” consists of the segments’ codewords: . There are two out-of-domain rows of elements each: and . These out-of-domain rows allow the verifier to compute and and hence . The DEEP-ALI verifier equates to the value of the AIR constraints applied to the revealed out-of-domain trace rows, after dividing out the zerofier.
Two DEEP updates (single-point quotients) link the two out-of-domain rows to the randomized quotient table, establishing the integrity of and .
Given rows of the quotient table, the distinguisher observes for each of the segments and indeterminates . Using the definition of for , we can replace by terms that only depend on and ultimately by terms that only depend on . With every replacement, the indeterminate is sent to a new value . It follows that every in-domain row is an invertible affine transformation of the vector , or equivalently, of the vector , where the concrete transformation depends on the quotient and on .
Consider the first out-of-domain row. After applying all possible substitutions, becomes . Let
the set of indeterminates in which is evaluated.
In total, there are elements revealed by the in-domain and 1 out-of-domain row. As long as , the revealed elements uniquely determine points on , for any fixed quotient and any admissible choice of . As long as , can be found by interpolation. It follows that under these conditions, any revealed combintation of in-domain and 1 out-of-domain row are independent of the quotient.
Finally, we show that . Because of the constraints on , distinct in-domain indeterminates give rise to distinct indeterminates for . In particular,
- is of size because of the multiplicative order of , and
- since all are sampled from the same coset, there is no such that , since that would imply be an element of a 2-adic subgroup, violating the second constraint on .
The prover must reject such that and have a non-empty intersection. In this case, contributes another distinct elements to , proving . In the non-interactive case, the probability of sampling a malicious is negligible and may safely by ignored.
Note that we cannot apply the same argument to the second out-of-domain row because after substitutions it maps to which repeats . Therefore, we must have a second argument to show that the second out-of-domain row is also independent of the trace, which follows below.
Consider the modified protocol where the prover sends not one -tuple of out-of-domain trace rows corresponding to the preimage of , but -many -tuples of out-of-domain trace rows corresponding to the preimages of for a primitive -th root of unity . The extra margin on the bound on the number of trace randomizers guarantees that even these extension-field rows are independent of the trace (as well as uniform). Consequently, the images of these -tuples are independent of the trace (though not necessarily uniform).
From the segmentation equation
one obtains a bijection between and . To see this, substitute for all of to obtain equations or one equation of -vectors involving an invertible matrix and an invertible Hadamard product.
It follows that the set is bijectively equivalent to . According to the definition of the randomized segments, and note that is exactly the first out-of-domain row of the randomized quotient table, which was already established to be independent of the trace (as well as uniform). Considering this first out-of-domain row fixed, there is also a bijective equivalence between and , which is exactly the second out-of-domain row. It follows that even this second out-of-domain row is a deterministic image of a variable that is independent of the trace.
Consequently, the distinguisher in the zero-knowledge game for this modified protocol cannot use this second out-of-domain row to his advantage. It follows that the distinguisher in the zero-knowledge game for the original protocol, which has strictly less information, cannot use it either.
Simulation
The simulator takes the trace, adjoins the batch-randomizer, and randomizes the trace polynomials authentically. There is no guarantee that the resulting quotient is low degree. However, after computing , the simulator factors for random values until a linear factor is found. The simulator proceeds to use this for the DEEP challenge along with a random quotient of the right degree such that to populate the quotient table with. The simulator randomizes the quotient table. All field elements in the transcript are, by the above arguments, guaranteed to be independent of the trace. Consequently, no distinguisher has any advantage over a random guess. Moreover, the switch between and ensures that the verifier accepts.
Zero-Knowledge of the Interactive and Non-Interactive Proofs
Zero-Knowledge IOP to Zero-Knowledge IP
BCS, §6 & §7 presents and analyzes the canonical IOP-to-NIROP transformation. The analysis shows that that transformation retains zero-knowledge.
Triton VM uses Merkle trees without salts (or any other form of hiding commitment scheme) but otherwise the same transformation. However, the BCS argument that zero-knowledge is retained, fails when this change is applied. So below we articulate a new one. This argument is specific to the context of STARKs and may fail in a more general IOP context.
The objects that are introduced by the BCS transform and that are a priori capable of leaking information are the Merkle authentication paths and Merkle roots. Without salts, these objects are images of data that should remain hidden.
Distinguish on the one hand Merkle trees built from the batch codeword, or from codewords downstream from it; from on the other hand, Merkle trees built from low-degree-extended trace or quotient tables. Since the batch contains a batch randomizer, the batch codeword is a uniformly random Reed-Solomon codeword and perfectly independent of the trace. Therefore, even if the complete list of leaf-preimages to this Merkle root or of any Merkle root of a codeword downstream from it were released, that release would leak no information about the trace. It follows that the Merkle roots and authentication paths (or authentication structures, in case they are compressed) corresponding to the batch codeword or codewords downstream from it are independent of the trace.
What remains is the Merkle trees built out of the low-degree-extended trace and quotient tables, with the important feature that both are randomized using the respective strategies described above. For these Merkle trees we quantitatively bound the the probability that information is leaked and show that this probability is negligible and concretely irrelevant.
Consider instead of the internal Merkle nodes and Merkle roots, the complete list of leafs, whose preimages are rows in the low-degree-extended trace and quotient tables. Clearly the Merkle authentication paths and roots can be computed from this information, so it suffices to bound the amount of information leaked by these leafs instead.
Consider the event in which the distinguisher recognizes one of these leaf digests because the digest appears as the image field of a list of preimage-and-image pairs produced by invoking the random oracle times. (These invocations may even happen after the distinguisher receives the transcript.) If this event happens then all bets about concealing the trace are off because the distinguisher can infer the value from one more row than accounted for. If this event does not happen, then all observed leaf digests are new and therefore leak no information about their corresponding preimages.
Consider first the low-degree-extended (and randomized) main trace. In order for the distinguisher to sample a preimage-and-image pair and row index whose image is observed as the leaf digest for that row, the distinguisher must make a correct guess at the entire set of main trace randomizers. (We consider the trace fixed.) The remaining 1 coefficient of margin on the number of randomizers per column means that there are (number of columns) variables left to guess. Any one preimage-image pair from the list corresponds to -many triples consisting of one preimage, one image, and one row index. So for every hash invocation, the distinguisher can test distinct guesses for the randomizers. The distinguisher is successful if he samples the correct set of main trace randomizers in any one of these guesses. The search space is so the probability of the distinguisher gleaning information from the main trace is no greater than .
An analogous argument holds for the auxiliary trace, where the number of columns is and the columns contain extension field elements. So the probability that the distinguisher gleans information from the auxiliary table is no greater than .
For the quotient table, and considering the randomizers used for quotient table randomization fixed, any given row corresponds to quotient segments and, via the segmentation equation, to values of the quotient . That quotient value itself corresponds to -many potential values of the -vector of randomized trace polynomials as preimages, where is at least , the number of constraints. The use of the term preimage here denotes not the inverse image of hash function evaluation but evaluation of the map that composes a) evaluation of the AIR constraints; b) division of the zerofiers; and c) taking the weighted linear sum.
If the AIR circuit is not injective, then and we bound as follows. Let be the degree of the AIR. Then there are monomials of degree or less in variables which correspond to a -tuple of in-or-out-of-domain rows. To see this, consider that a there are slots on a line to fill with stars and bars and the resulting arrangement corresponds bijectively to a monomial of exactly degree in variables. Interpret the one extra variable as an imaginary one used to homogenize all monomials of non-max degree; then there are monomials of degree at most in variables.
Any value of the quotient is a linear combination of these monomials. It follows that the number of corresponding -tuples of -vectors of randomized trace values is bounded by .
Therefore, whenever the distinguisher tests a candidate quotient row and finds that its hash is different from any leaf digest in the transcript, he can discount at most candidate -vectors of trace randomizers as viable candidates. The total number of discountable candidates is at most , which sounds large until you realize that the search space is . The probability of the distinguisher gleaning information from the quotient table is therefore bounded by
In conclusion, the probability that the computationally bounded distinguisher, who limits himself to invocations of the random oracle, finds in the transcript one of the responses to his random oracle queries, is bounded by
Zero-Knowledge IP to Zero-Knowledge NIP
Applying the Fiat-Shamir transform does not affect the distribution of the transcript. It does, however, affect the simulator who needs to know the value of the challenge before producing the commitments from which it is pseudorandomly derived. To achieve this, the simulator is defined relative to the programmable random oracle model, which enables him to specify (a sparse list of) query-response pairs that the random oracle must abide by.
Zero-Integral and Sum-Check
Let be a table of 1 column and rows, and let be any polynomial that agrees with when evaluated on , where is a generator of the subgroup of order . Group theory lets us prove and efficiently verify if .
Decompose into , where is the zerofier over , and where has degree at most . The table sums to zero if and only if integrates to zero over because
and this latter proposition is true if and only if the constant term of is zero.
Theorem. for a subgroup of order .
Let be a subgroup of . If then and also because the elements of come in pairs: . Therefore .
The map is a morphism of groups with . Therefore we have:
The polynomial has only one term whose exponent is , which is the constant term.
This observation gives rise to the following Polynomial IOP for verifying that a polynomial oracle integrates to 0 on a subgroup of order some power of 2.
Protocol Zero-Integral
- Prover computes and .
- Prover computes .
- Prover sends , of degree at most , and , of degree at most to Verifier.
- Verifier queries , , in and receives .
- Verifier tests .
This protocol can be adapted to show instead that a given polynomial oracle integrates to on the subgroup , giving rise to the well-known Sum-Check protocol. The adaptation follows from the Verifier’s capacity to simulate from , where . This simulated polynomial is useful because
In other words, integrates to on iff integrates to on , and we already a protocol to establish the latter claim.